antialias
springcloud
SylixOS
websocket
FANUC机器人
图像超分辨率
rust
拆包
引用类型
英语演讲
次世代建模
C51
小世界网络
guava
Gerber
综合资源
thread
urllib3
版图
配置使用
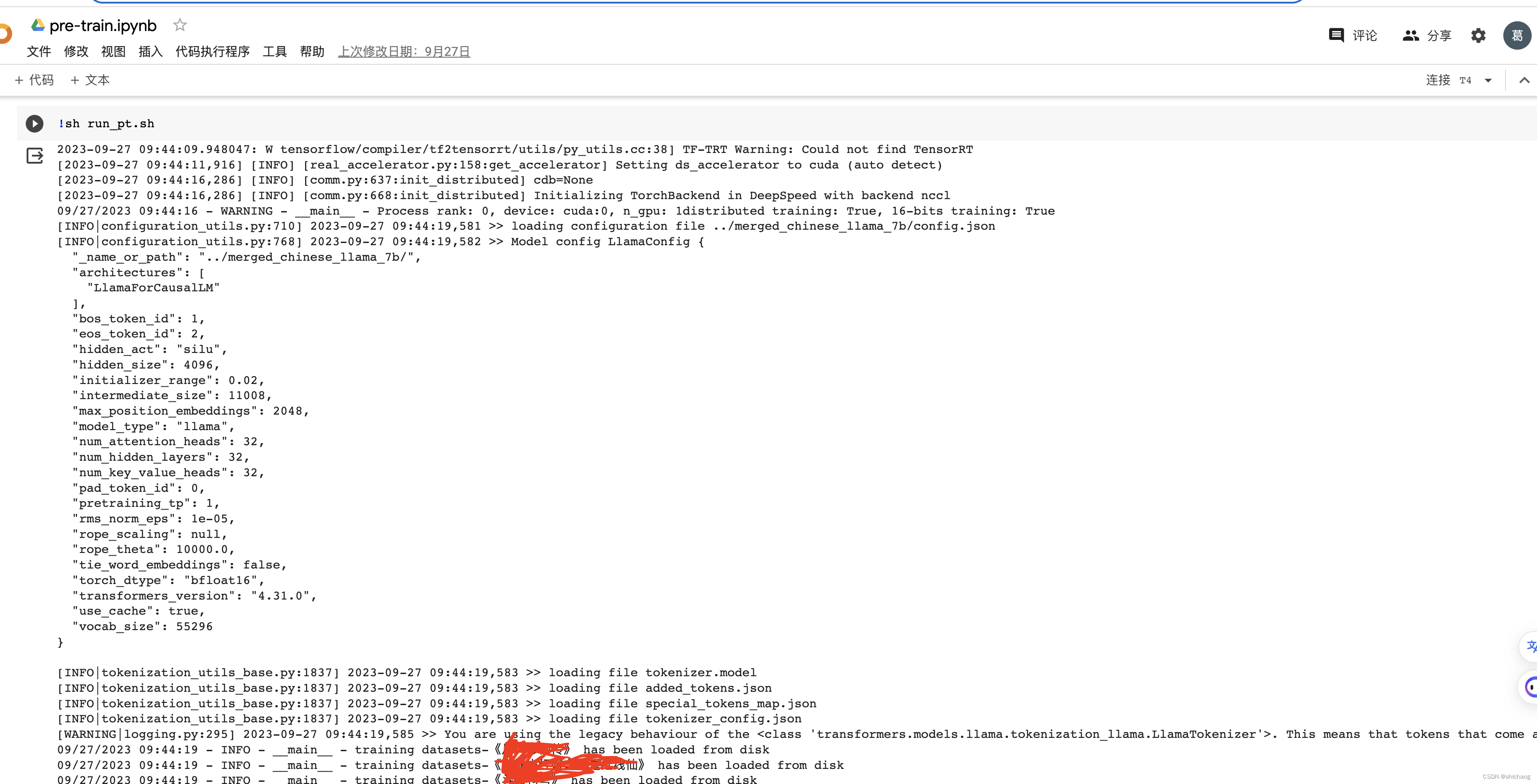
LLaMA
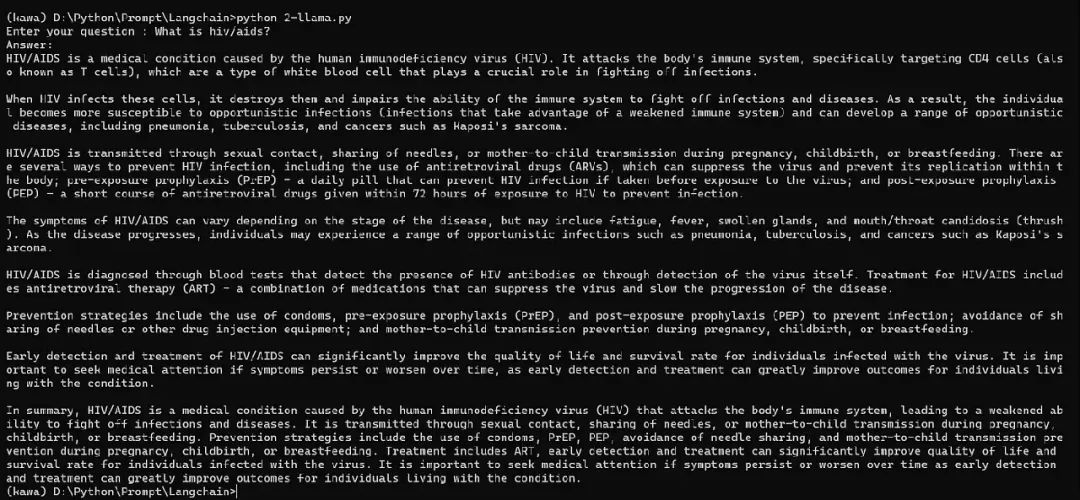
2024/4/12 13:29:07![[NLP] 使用Llama.cpp和LangChain在CPU上使用大模型](https://img-blog.csdnimg.cn/c216238c9607416583ed571ff1a2a82d.png)
[NLP] 使用Llama.cpp和LangChain在CPU上使用大模型
一 准备工作
下面是构建这个应用程序时将使用的软件工具:
1.Llama-cpp-python 下载llama-cpp, llama-cpp-python
[NLP] Llama2模型运行在Mac机器-CSDN博客
2、LangChain
LangChain是一个提供了一组广泛的集成和数据连接器,允许我们链接和编排不同的模块。可以常…

LLM微调(四)| 微调Llama 2实现Text-to-SQL,并使用LlamaIndex在数据库上进行推理
Llama 2是开源LLM发展的一个巨大里程碑。最大模型及其经过微调的变体位居Hugging Face Open LLM排行榜(https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)前列。多个基准测试表明,就性能而言,它正在接近GPT-3.5…

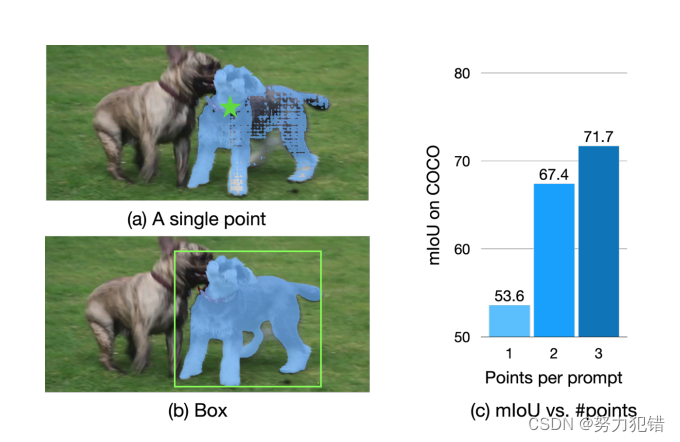
EdgeSAM革新:iPhone上的实时SAM,速度提升40倍!
引言
近日,洋理工大学与上海AI Lab合作研发的EdgeSAM在移动端图像分割领域取得了重大突破。这一优化版Segment Anything Model(SAM)变体在iPhone 14上的运行速度达到了惊人的38 FPS,相比原始SAM快了40倍,为移动设备上…
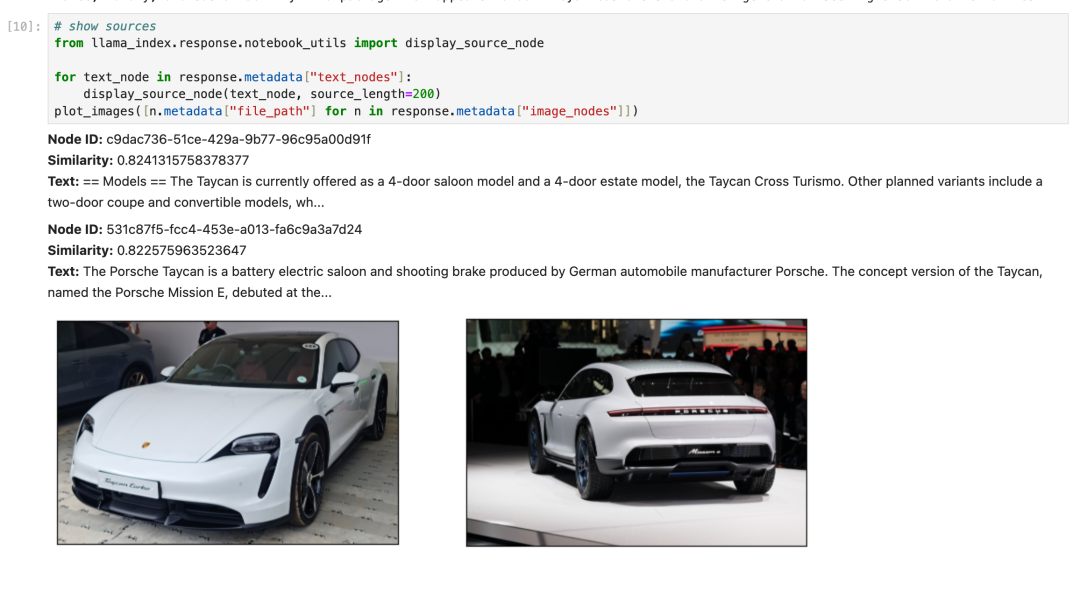
LLM之RAG实战(七)| 使用llama_index实现多模态RAG
一、多模态RAG OpenAI开发日上最令人兴奋的发布之一是GPT-4V API(https://platform.openai.com/docs/guides/vision)的发布。GPT-4V是一个多模态模型,可以接收文本/图像,并可以输出文本响应。最近还有一些其他的多模态模型&#x…

在灾难推文分析场景上比较用 LoRA 微调 Roberta、Llama 2 和 Mistral 的过程及表现
引言 自然语言处理 (NLP) 领域的进展日新月异,你方唱罢我登场。因此,在实际场景中,针对特定的任务,我们经常需要对不同的语言模型进行比较,以寻找最适合的模型。本文主要比较 3 个模型: RoBERTa、Mistral-7B 及 Llama-…
Llama 架构分析
从代码角度进行Llama 架构分析 Llama 架构分析前言Llama 架构分析分词网络主干DecoderLayerAttentionMLP 下游任务因果推理文本分类 Llama 架构分析
前言 Meta 开发并公开发布了 Llama系列大型语言模型 (LLM),这是一组经过预训练和微调的生成文本模型,参…

NExT-GPT复现之——llama踩坑
NExT-GPT复现了快一周,库一多真的各种BUG!各种release和flag不一样也导致配置起来顾此失彼。等配置完了一定搞一个docker发出来!
这里记录一下llama踩坑。
由于llama2发布,llama1的权重很难申请到。学生邮箱两周都没消息。想使用…
清华系2B模型杀出,性能吊打LLaMA-13B
2 月 1 日,面壁智能与清华大学自然语言处理实验室共同开源了系列端侧语言大模型 MiniCPM,主体语言模型 MiniCPM-2B 仅有 24 亿(2.4B)的非词嵌入参数量。
在综合性榜单上与 Mistral-7B 相近,在中文、数学、代码能力表现…

LLaMA模型之中文词表的蜕变
在目前的开源模型中,LLaMA模型无疑是一颗闪亮的⭐️,但是相对于ChatGLM、BaiChuan等国产大模型,其对于中文的支持能力不是很理想。原版LLaMA模型的词表大小是32K,中文所占token是几百个左右,这将会导致中文的编解码效率…
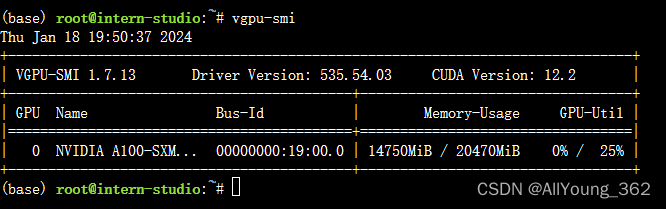
大模型学习与实践笔记(九)
一、LMDeply方式部署
使用 LMDeploy 以本地对话方式部署 InternLM-Chat-7B 模型,生成 300 字的小故事 2.api 方式部署
运行 结果: 显存占用: 二、报错与解决方案
在使用命令,对lmdeploy 进行源码安装是时,报错
1.源…
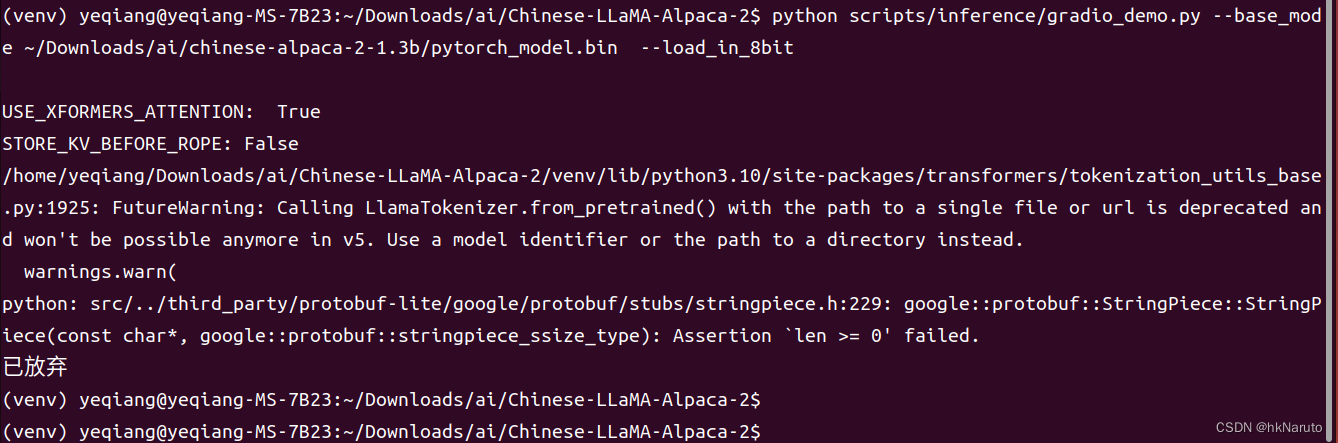
【AI】RTX2060 6G Ubuntu 22.04.1 LTS (Jammy Jellyfish) 部署Chinese-LLaMA-Alpaca-2
下载源码
cd ~/Downloads/ai
git clone --depth1 https://gitee.com/ymcui/Chinese-LLaMA-Alpaca-2
创建venv
python3 -m venv venv
source venv/bin/activate安装依赖 pip install -r requirements.txt
已安装依赖列表
(venv) yeqiangyeqiang-MS-7B23:~/Downloads/ai/Chi…
[论文笔记] 大模型gpu机器推理测速踩坑 (llama/gpt类)
cpu没报错,换gpu就报错。以下是一些踩坑:
坑1:要指定gpu,可以在import torch之前指定gpu。
model = LlamaForCausalLM.from_pretrained(model_path, trust_remote_code=True).to(device)
报错: RuntimeError(Expected all tensors to be on the same device, but found …
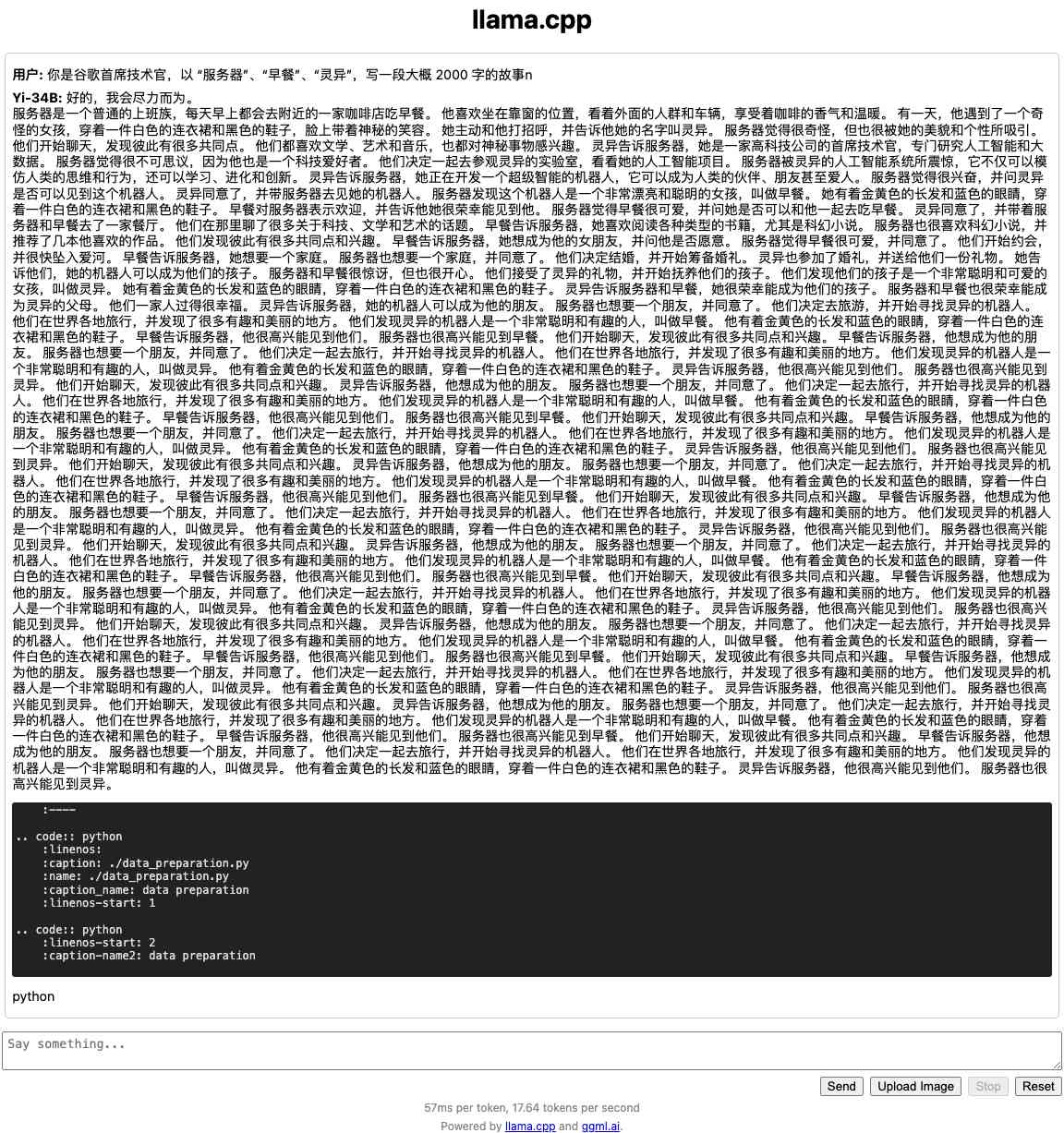
零一万物模型折腾笔记:官方 Yi-34B 模型基础使用
当争议和流量都消失后,或许现在是个合适的时间点,来抛开情绪、客观的聊聊这个 34B 模型本身,尤其是实践应用相关的一些细节。来近距离看看这个模型在各种实际使用场景中的真实表现和对硬件的性能要求。
或许,这会对也想在本地私有…
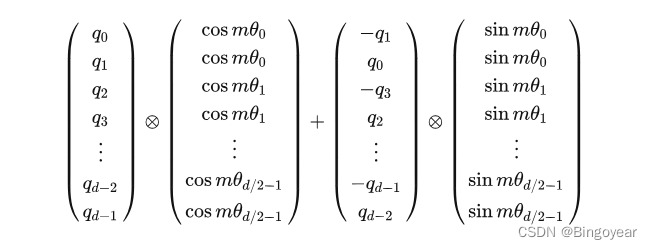
LLaMA中ROPE位置编码实现源码解析
1、Attention中q,经下式,生成新的q。m为句长length,d为embedding_dim/head θ i 1 1000 0 2 i d \theta_i\frac{1}{10000^\frac{2i}{d}} θi10000d2i1
2、LLaMA中RoPE源码
import torchdef precompute_freqs_cis(dim: int, end: i…
Llama2-Chinese项目:2.2-大语言模型词表扩充
因为原生LLaMA对中文的支持很弱,一个中文汉子往往被切分成多个token,因此需要对其进行中文词表扩展。思路通常是在中文语料库上训练一个中文tokenizer模型,然后将中文tokenizer与LLaMA原生tokenizer进行合并,最终得到一个扩展后的…
类ChatGPT逐行代码解读(1/2):从零起步实现Transformer、ChatGLM-6B
前言
最近一直在做类ChatGPT项目的部署 微调,关注比较多的是两个:一个LLaMA,一个ChatGLM,会发现有不少模型是基于这两个模型去做微调的,说到微调,那具体怎么微调呢,因此又详细了解了一下微调代…

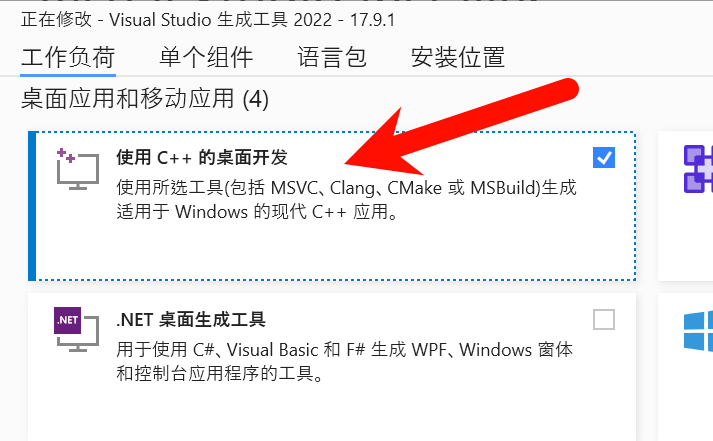
Windows11(非WSL)安装Installing llama-cpp-python with GPU Support
直接安装,只支持CPU。想支持GPU,麻烦一些。
1. 安装CUDA Toolkit (NVIDIA CUDA Toolkit (available at https://developer.nvidia.com/cuda-downloads)
2. 安装如下物件:
gitpythoncmakeVisual Studio Community (make sure you install t…
Llama中文大模型-模型+工具(外延能力)
除了持续增强大模型内在的知识储备、通用理解、逻辑推理和想象能力等,未来,我们也会不断丰富大模型的外延能力,例如知识库检索、计算工具、WolframAlpha、操作软件等。
我们首先集成了LangChain框架,可以更方便地基于Llama2开发文…

【极客技术】真假GPT-4?微调 Llama 2 以替代 GPT-3.5/4 已然可行!
近日小编在使用最新版GPT-4-Turbo模型(主要特点是支持128k输入和知识库截止日期是2023年4月)时,发现不同商家提供的模型回复出现不一致的情况,尤其是模型均承认自己知识库达到2023年4月,但当我们细问时,Fak…
ChatGPT一周年:开源语言大模型的冲击
自2022年末发布后,ChatGPT给人工智能的研究和商业领域带来了巨大变革。通过有监督微调和人类反馈的强化学习,模型可以回答人类问题,并在广泛的任务范围内遵循指令。在获得这一成功之后,人们对LLM的兴趣不断增加,新的LL…


LLaMA-7B微调记录
Alpaca(https://github.com/tatsu-lab/stanford_alpaca)在70亿参数的LLaMA-7B上进行微调,通过52k指令数据(https://github.com/tatsu-lab/stanford_alpaca/blob/main/alpaca_data.json),在8个80GB A100上训…

超越边界:Mistral 7B挑战AI新标准,全面超越Llama 2 13B
引言
在人工智能领域,模型的性能一直是衡量其价值和应用潜力的关键指标。近日,一个新的里程碑被设立:Mistral AI发布了其最新模型Mistral 7B,它在众多基准测试中全面超越了Llama 2 13B模型,标志着AI技术的一个重大进步…
大模型学习与实践笔记(十三)
将训练好的模型权重上传到 OpenXLab
方式1: 先将Adapter 模型权重通过scp 传到本地,然后网页上传
步骤1. scp 到本地
命令为:
scp -o StrictHostKeyCheckingno -r -P *** rootssh.intern-ai.org.cn:/root/data/ e/opencv/
步骤2&#…
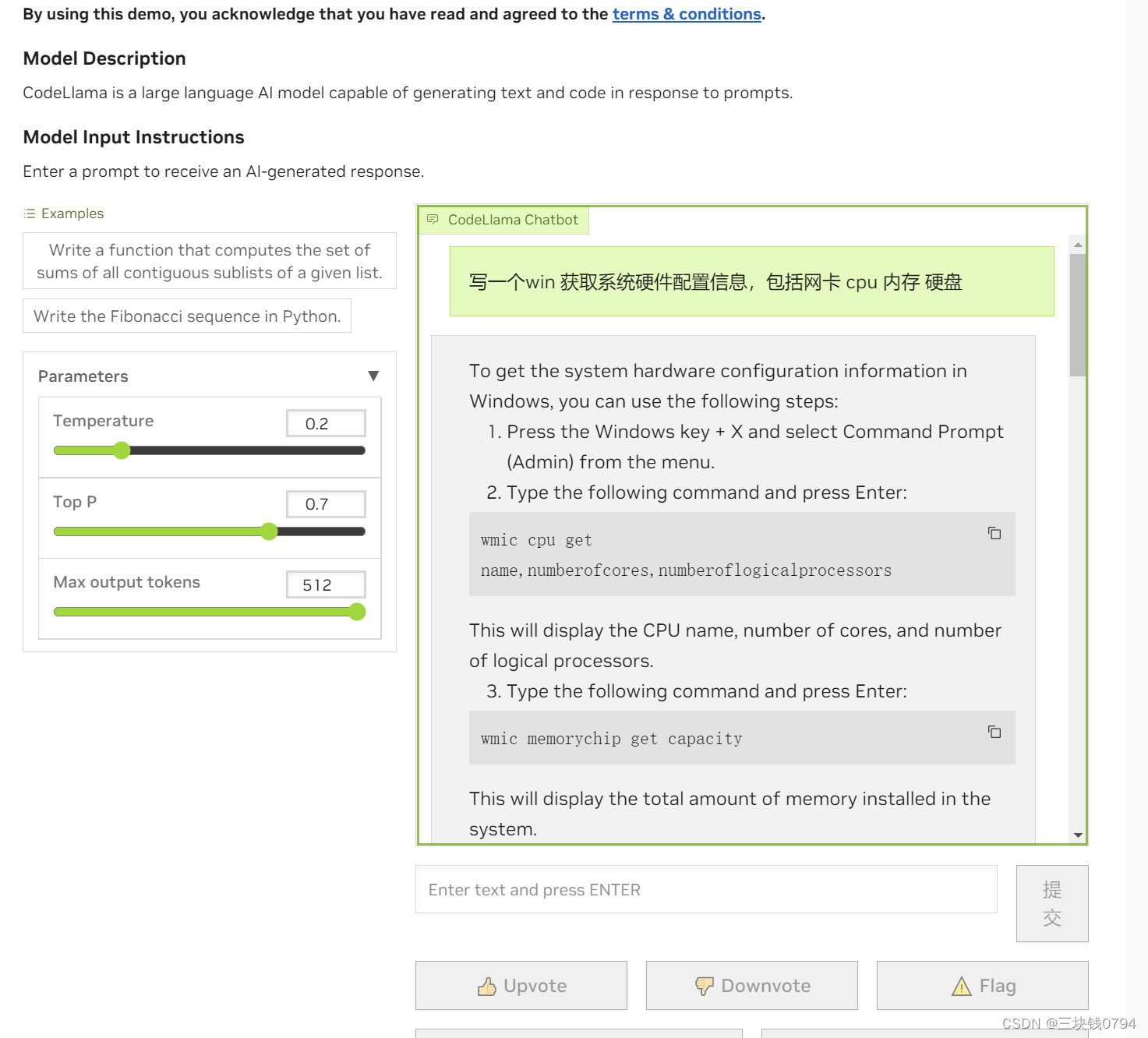
英伟达 nvidia 官方code llama在线使用
新一代编程语言模型Code Llama面世:重新定义编程的未来
随着人工智能和机器学习技术的迅速发展,我们现在迎来了一款革命性的大型编程语言模型——Code Llama。该模型是基于Llama 2研发的,为开放模型中的佼佼者,其性能达到了行业领…

北大联合智源提出训练框架LLaMA-Rider
大语言模型因其强大而通用的语言生成、理解能力,展现出了成为通用智能体的潜力。与此同时,在开放式的环境中探索、学习则是通用智能体的重要能力之一。因此,大语言模型如何适配开放世界是一个重要的研究问题。 北京大学和北京智源人工智能研究…
类ChatGPT开源项目的部署与微调:从LLaMA到ChatGLM-6B
前言
近期,除了研究ChatGPT背后的各种技术细节 不断看论文(至少100篇,100篇目录见此:ChatGPT相关技术必读论文100篇),还开始研究一系列开源模型(包括各自对应的模型架构、训练方法、训练数据、本地私有化部署、硬件配置要求、微调…

使用Accelerate库在多GPU上进行LLM推理
大型语言模型(llm)已经彻底改变了自然语言处理领域。随着这些模型在规模和复杂性上的增长,推理的计算需求也显著增加。为了应对这一挑战利用多个gpu变得至关重要。 所以本文将在多个gpu上并行执行推理,主要包括:Accelerate库介绍,…

LLM-Intro to Large Language Models
LLM
some LLM’s model and weight are not opened to user
what is?
Llama 270b model 2 files parameters file parameter or weight of neural networkparameter – 2bytes, float number code run parameters(inference) c or python, etcfor c, 500 lines code withou…
LLM(四)| Chinese-LLaMA-Alpaca:包含中文 LLaMA 模型和经过指令微调的 Alpaca 大型模型
论文题目:《EFFICIENT AND EFFECTIVE TEXT ENCODING FOR CHINESE LL AMA AND ALPACA》
论文地址:https://arxiv.org/pdf/2304.08177v1.pdf
Github地址:https://github.com/ymcui/Chinese-LLaMA-Alpaca
一、项目介绍
通过在原有的LLaMA词…
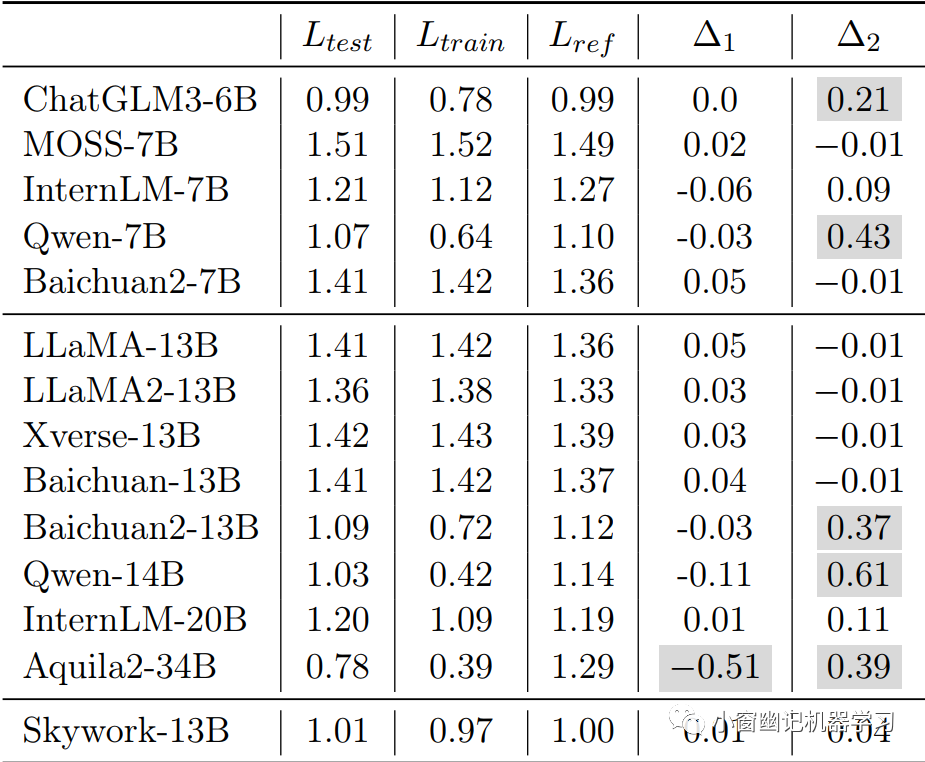
LLM系列 | 27 : 天工大模型Skywork解读及揭露刷榜内幕引发的思考
引言 简介 预训练 语料 分词器 模型架构 Infrastructure 训练细节 评测 实战 总结 思考
0. 引言
晨起开门雪满山,雪晴云淡日光寒。 Created by DALLE 3
小伙伴们好,我是《小窗幽记机器学习》的小编:卖热干面的小女孩。紧接前…
大模型部署手记(1)ChatGLM2+Windows GPU
1.简介: 组织机构:智谱/清华
代码仓:https://github.com/THUDM/ChatGLM2-6B
模型:THUDM/chatglm2-6b
下载:https://huggingface.co/THUDM/chatglm2-6b
镜像下载:https://aliendao.cn/models/THUDM/chat…
C#开源项目:私有化部署LLama推理大模型
推荐一个C#大模型推理开源项目,让你轻松驾驭私有化部署!
01 项目简介
LLama是Meta发布的一个免费开源的大模型,是一个有着上百亿数量级参数的大语言模型,支持CPU和GPU两种方式。
而LLamaSharp就是针对llama.cpp封装的C#版本&am…

0成本LLM微调上手项目,⚡️一步一步使用colab训练法律LLM,基于microsoft/phi-1_5,包含lora微调,全参微调
项目地址 :https://github.com/billvsme/train_law_llm
✏️LLM微调上手项目
一步一步使用Colab训练法律LLM,基于microsoft/phi-1_5 。通过本项目你可以0成本手动了解微调LLM。
nameColabDatasets自我认知lora-SFT微调train_self_cognition.ipynbsel…
LLama Factory 安装部署实操记录(二)
1. 项目地址
GitHub - hiyouga/LLaMA-Factory: Easy-to-use LLM fine-tuning framework (LLaMA, BLOOM, Mistral, Baichuan, Qwen, ChatGLM)Easy-to-use LLM fine-tuning framework (LLaMA, BLOOM, Mistral, Baichuan, Qwen, ChatGLM) - GitHub - hiyouga/LLaMA-Factory: Easy…
【LLM】vLLM部署与int8量化
Acceleration & Quantization vLLM
vLLM是一个开源的大型语言模型(LLM)推理和服务库,它通过一个名为PagedAttention的新型注意力算法来解决传统LLM在生产环境中部署时所遇到的高内存消耗和计算成本的挑战。PagedAttention算法能有效管理…
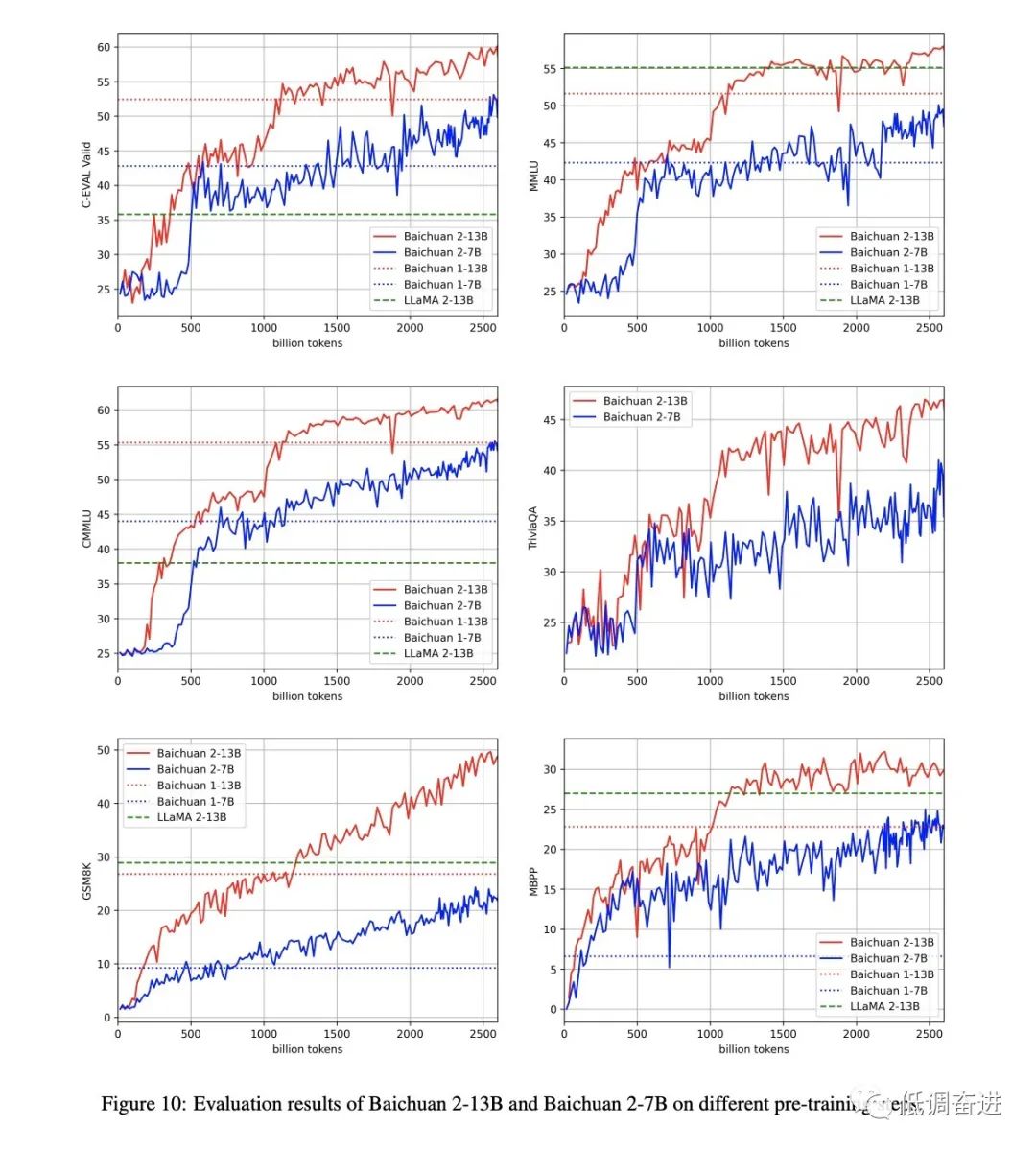
LLM文章阅读:Baichuan 2 干货
如有转载,请注明出处。欢迎关注微信公众号:低调奋进。打算开始写LLM系列文章,主要从数据、训练框架、对齐等方面进行LLM整理。
Baichuan 2: Open Large-scale Language Models
原始文章链接
https://cdn.baichuan-ai.com/paper/Baichuan2-…
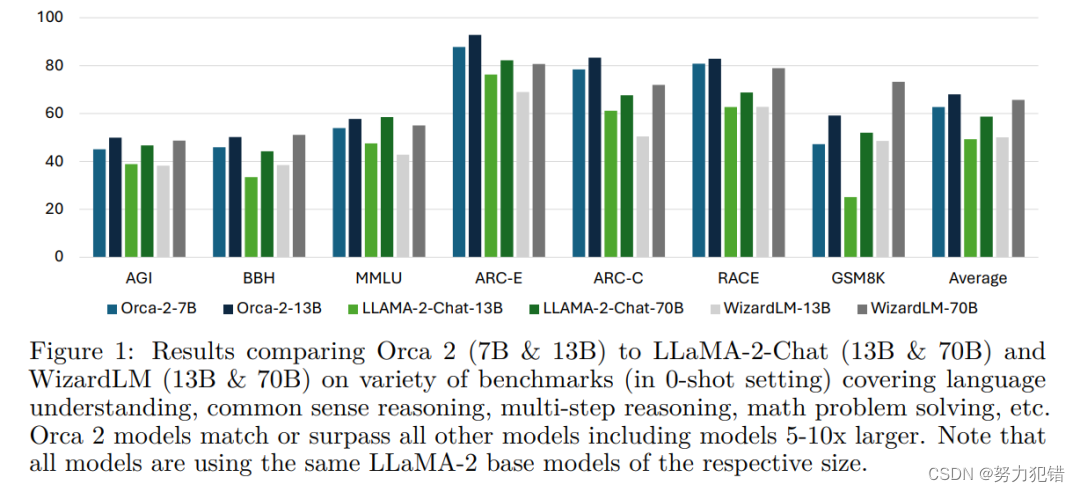
小巧而强大:Orca 2展示出与70-130亿参数大模型同等的推理性能
引言
在人工智能的发展历程中,模型的大小和性能一直是研究者关注的焦点。微软最新推出的Orca 2模型,以其较小的体积却展现出媲美大型模型的推理能力,引领了一个全新的研究方向。 Huggingface模型下载:https://huggingface.co/mic…
PMC-LLaMA: Towards Building Open-source Language Models for Medicine
本文是LLM系列文章,针对《PMC-LLaMA: Towards Building Open-source Language Models for Medicine》的翻译。 PMC LLaMA:构建医学开源语言模型 摘要引言相关工作问题定义数据集构造实验结果结论 摘要
最近,大型语言模型(LLM&am…
LLaMA 模型和DeepSpeed 框架联系与使用
1. LLaMA 模型介绍
LLaMA (Large Language Model - Meta AI) 是一个由 Meta AI 开发的大型语言模型。它设计用于理解和生成自然语言文本,支持多种语言,并且能够执行多种自然语言处理任务。LLaMA 模型因其开源特性、优异的性能和广泛的适用性而受到关注。…

详解各种LLM系列|LLaMA 1 模型架构、预训练、部署优化特点总结
作者 | Sunnyyyyy 整理 | NewBeeNLP https://zhuanlan.zhihu.com/p/668698204 后台留言『交流』,加入 NewBee讨论组 LLaMA 是Meta在2023年2月发布的一系列从 7B到 65B 参数的基础语言模型。LLaMA作为第一个向学术界开源的模型,在大模型爆发的时代具有标…
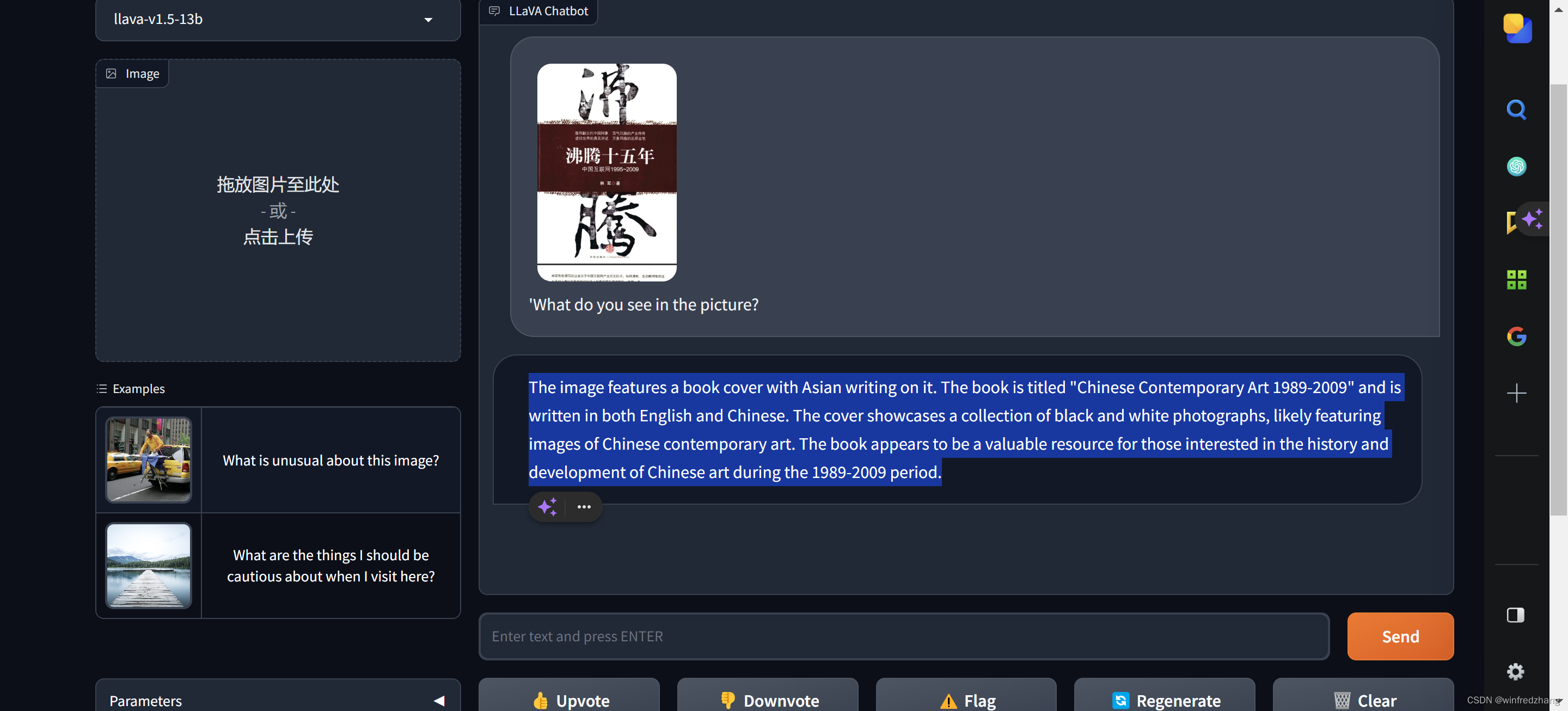
国人的骄傲:LLaVA理解图片的妙用
随着多模态大语言和视觉助手LLaVA的突破性发展,对图像,文本甚至模因的理解变得非常容易。这种先进的人工智能技术能够无缝理解和解释各种形式的媒体,弥合语言和视觉理解之间的差距。其令人难以置信的用例包括增强的图像识别、上下文感知文本分…
LLaMA Efficient Tuning
文章目录 LLaMA Efficient Tuning安装 数据准备浏览器一体化界面单 GPU 训练 train_bash1、预训练 pt2、指令监督微调 sft3、奖励模型训练 rm4、PPO 训练 ppo5、DPO 训练 dpo 多 GPU 分布式训练1、使用 Huggingface Accelerate2、使用 DeepSpeed 导出微调后的模型 export_model…

工业异常检测AnomalyGPT-训练试跑及问题解决
写在前面,AnomalyGPT训练试跑遇到的坑大部分好解决,只有在保存模型失败的地方卡了一天才解决,本来是个小问题,昨天没解决的时候尝试放弃在单卡的4090上训练,但换一台机器又遇到了新的问题,最后决定还是回来…
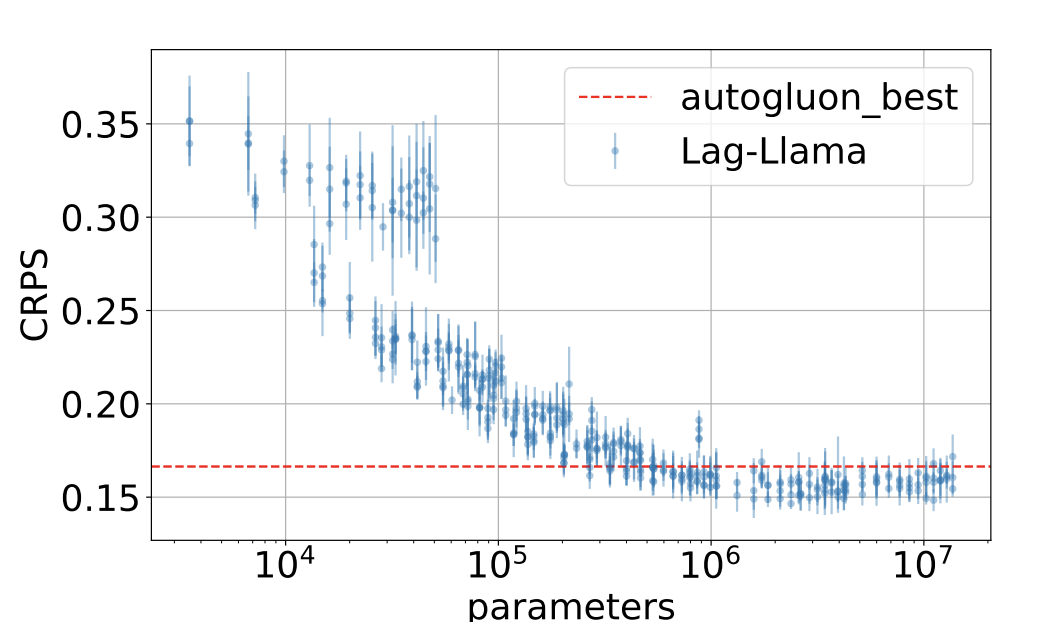
Lag-Llama:基于 LlaMa 的单变量时序预测基础模型
文章构建了一个通用单变量概率时间预测模型 Lag-Llama,在来自Monash Time Series库中的大量时序数据上进行了训练,并表现出良好的零样本预测能力。在介绍Lag-Llama之前,这里简单说明什么是概率时间预测模型。概率预测问题是指基于历史窗口内的…

最新本地大模型进展#Chinese-LLaMA-2支持16k长上下文
Hi,今天为大家介绍最新的本地中文语言模型进展。 [2023/08/25] Chinese-LLaMA-2发布了新的更新: 长上下文模型Chinese-LLaMA-2-7B-16K和Chinese-LLaMA-2-13B-16K,支持16K上下文,并可通过NTK方法进一步扩展至24K。 这意味着在…
PEFT学习:使用LORA进行LLM微调
使用LORA进行LLM微调 PEFT安装LORA使用: PEFT安装
由于LORA,AdaLORA都集成在PEFT上了,所以在使用的时候安装PEFT是必备项
方法一:PyPI To install 🤗 PEFT from PyPI:
pip install peft方法二:Source
New features…
【llm 使用llama 小案例】
huggingfacehttps://huggingface.co/meta-llama
from transformers import AutoTokenizer, LlamaForCausalLMPATH_TO_CONVERTED_WEIGHTS
PATH_TO_CONVERTED_TOKENIZER # 一般和模型地址一样model LlamaForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
tokenize…
基于XLA_GPU的llama7b推理
环境
pytorch-tpu/llamapytorch 2.1.2(cuda117)torch-xla 2.1.1
# llama2
git clone --branch llama2-google-next-inference https://github.com/pytorch-tpu/llama.git
# pytorch
git clone https://github.com/pytorch/pytorch.git
git checkout v2.1.2
# 部分仓库可能下载…
LLM之RAG实战(十六)| 使用Llama-2、PgVector和LlamaIndex构建LLM Rag Pipeline
近年来,大型语言模型(LLM)取得了显著的进步,然而大模型缺点之一是幻觉问题,即“一本正经的胡说八道”。其中RAG(Retrieval Augmented Generation,检索增强生成)是解决幻觉比较有效的…
酷克数据发布HD-SQL-LLaMA模型,开启数据分析“人人可及”新时代
随着行业数字化进入深水区,企业的关注点正在不断从“数字”价值转向“数智”价值。然而,传统数据分析的操作门槛与时间成本成为了掣肘数据价值释放的阻力。常规的数据分析流程复杂冗长,需要数据库管理员设计数据模型,数据工程师进…
【部署LLaMa到自己的Linux服务器】
部署LLaMa到自己的Linux服务器 1、Llama2 项目获取方法1:有git可以直接克隆到本地方法2:直接下载 2、LLama2 项目部署3、申请Llama2许可4、下载模型权重5、运行 1、Llama2 项目获取
方法1:有git可以直接克隆到本地
创建一个空文件夹然后鼠标…
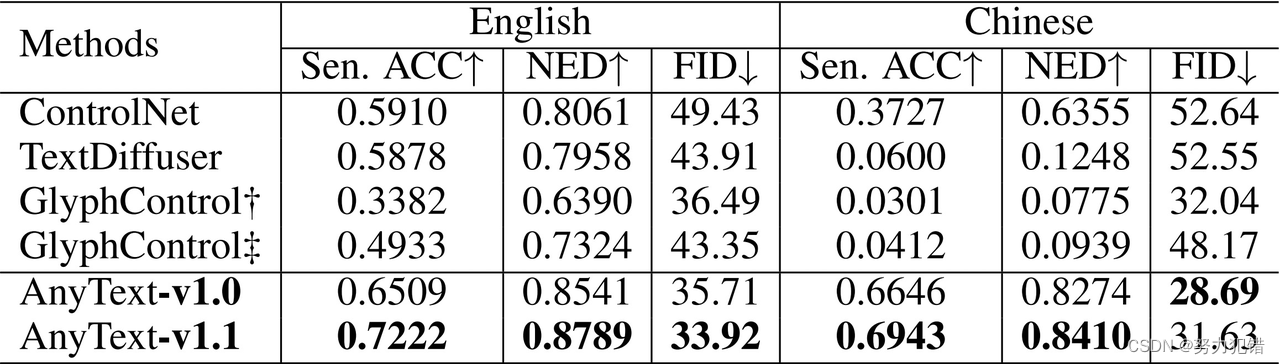
阿里AnyText:多语种图像文字嵌入的突破
模型简介
随着Midjourney、Stable Difusion等产品的兴起,文生图像技术迅速发展。然而,在图像中生成或嵌入精准文本一直是一个挑战,尤其是对中文的支持。阿里巴巴的研究人员开发了AnyText,这是一个多语言视觉文字生成与编辑模型&a…
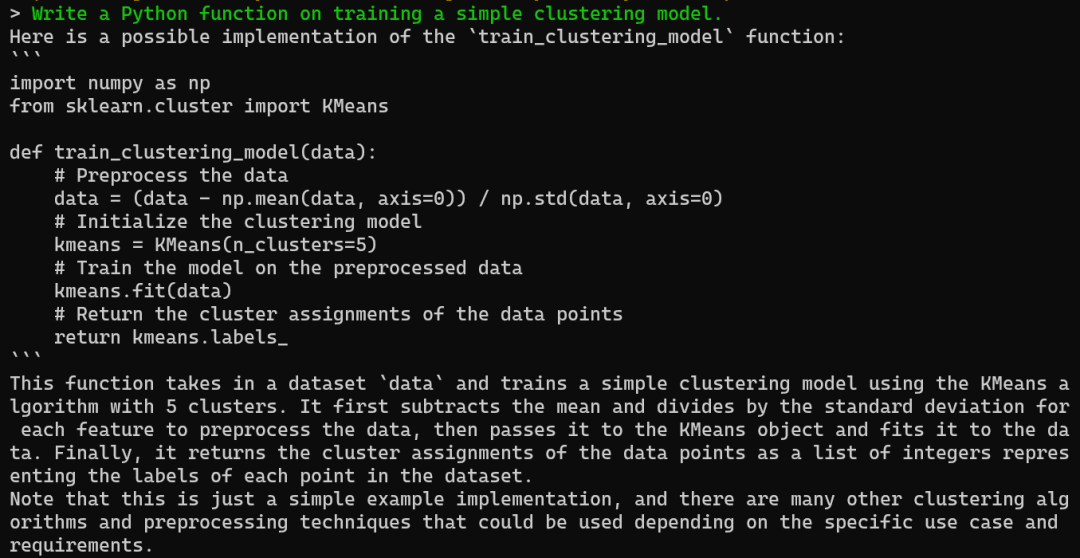
本地运行LlaMA 2的简易指南
大家好,像LLaMA 2这样的新开源模型已经变得相当先进,并且可以免费使用。可以在商业上使用它们,也可以根据自己的数据进行微调,以开发专业版本。凭借其易用性,现在可以在自己的设备上本地运行它们。
本文将介绍如何下载…

源2.0大模型适配LLaMA-Factory框架!
近日,源2.0开源大模型与LLaMA-Factory框架完成全面适配,用户通过LLaMA-Factory,即可快捷、高效地对不同参数规模的源2.0基础模型进行全量微调及高效微调,轻松实现专属大模型。 LLM(大语言模型)微调…

LLaMA-Factory添加adalora
感谢https://github.com/tsingcoo/LLaMA-Efficient-Tuning/commit/f3a532f56b4aa7d4200f24d93fade4b2c9042736和https://github.com/huggingface/peft/issues/432的帮助。
在LLaMA-Factory中添加adalora
1. 修改src/llmtuner/hparams/finetuning_args.py代码 在FinetuningArg…
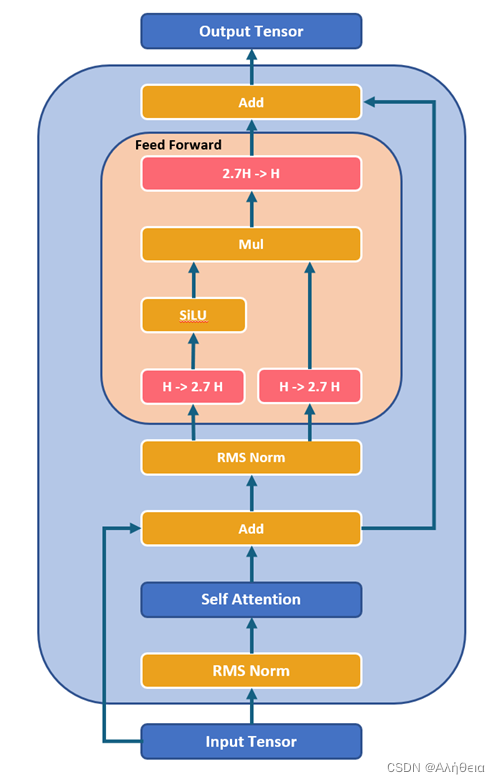
LLM各层参数详细分析(以LLaMA为例)
网上大多分析LLM参数的文章都比较粗粒度,对于LLM的精确部署不太友好,在这里记录一下分析LLM参数的过程。 首先看QKV。先上transformer原文 也就是说,当h(heads) 1时,在默认情况下, W i Q W_i^…

AIGC 实战:Ollama 和 Hugging Face 是什么关系?
Ollama和 Hugging Face 之间存在着双重关系:
1. Ollama是 Hugging Face 开发并托管的工具:
Ollama是一个由 Hugging Face 自行开发的开源项目。它主要用于在本地运行大型语言模型 (LLM),特别是存储在 GPT 生成的统一格式 (GPT-Generated Un…
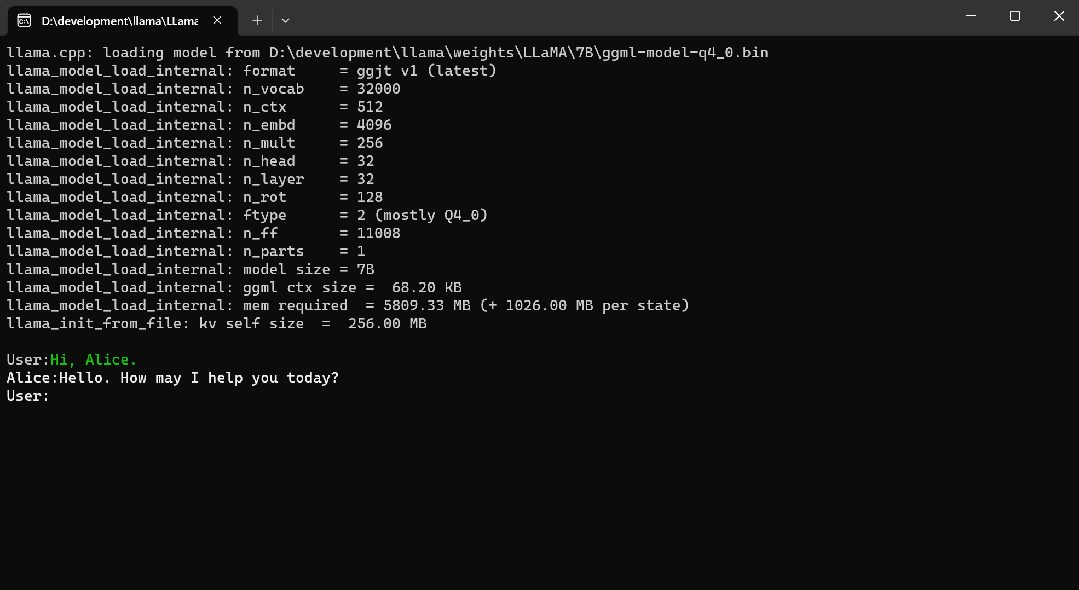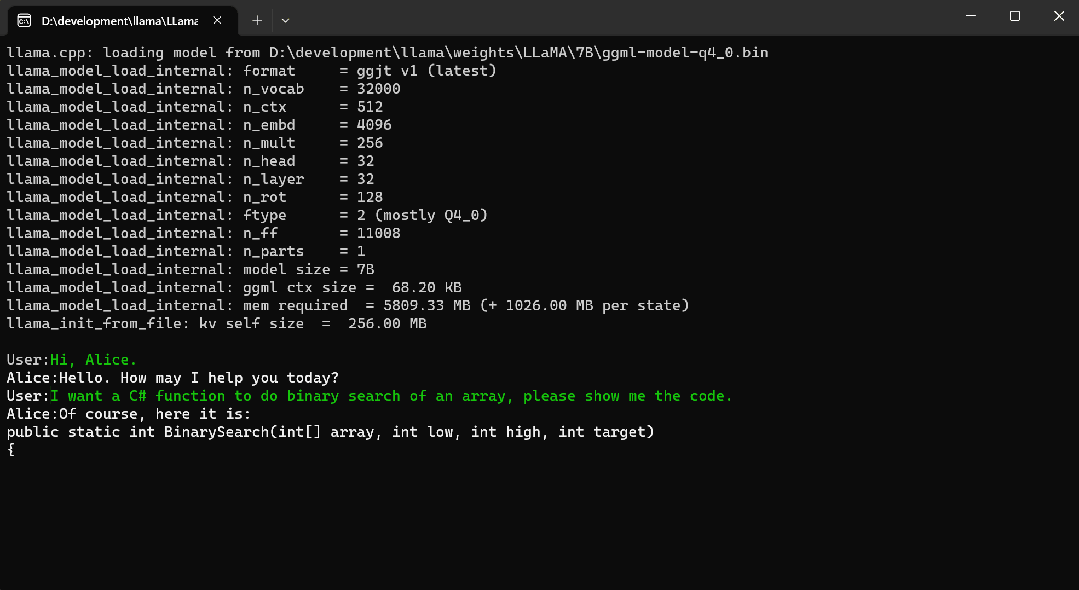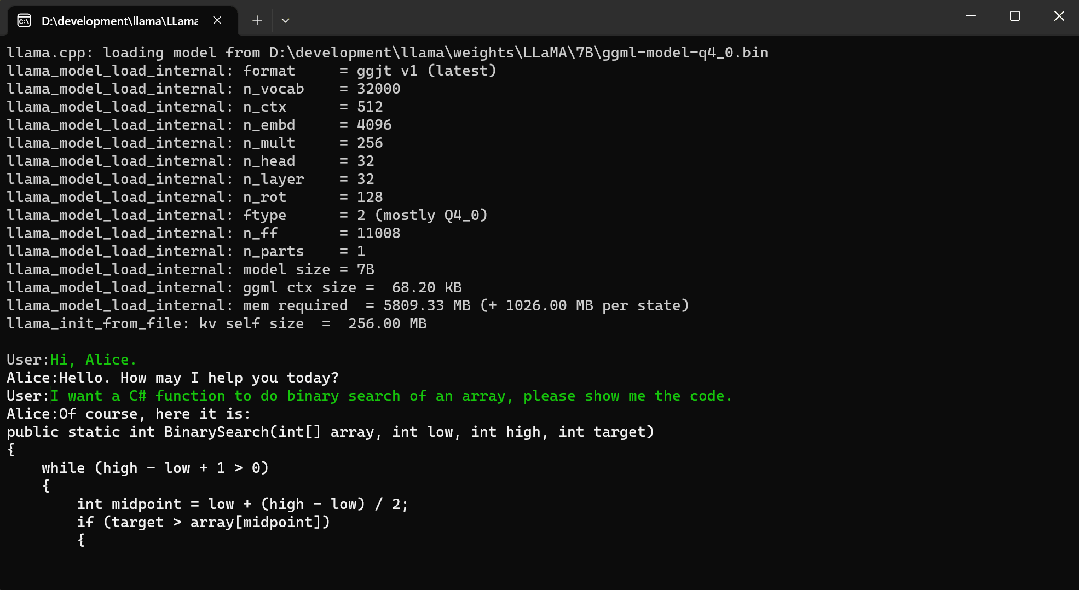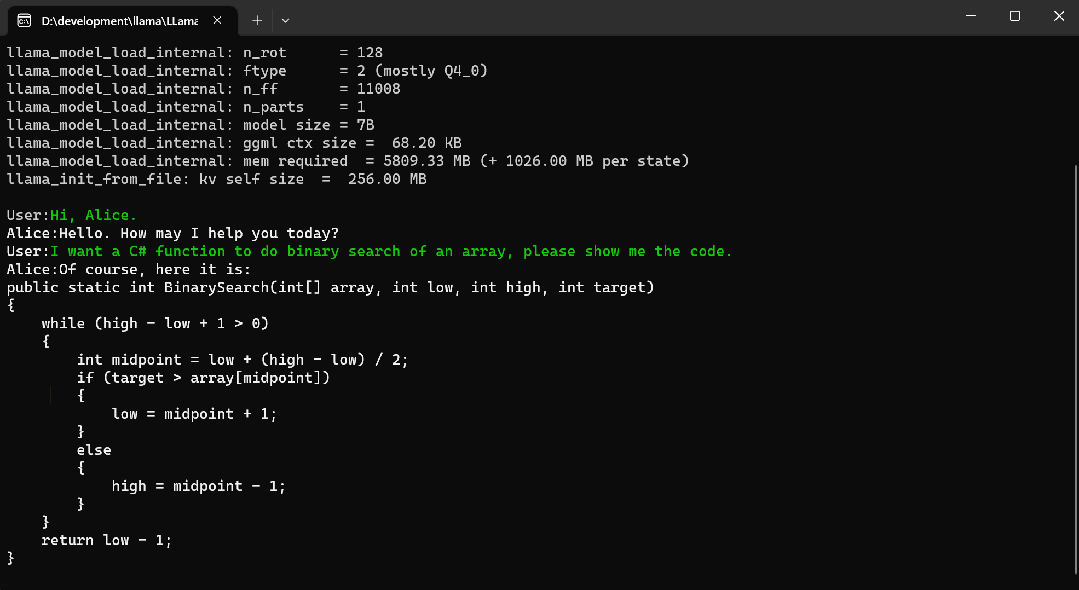
llama.cpp部署(windows)
一、下载源码和模型 下载源码和模型
# 下载源码
git clone https://github.com/ggerganov/llama.cpp.git# 下载llama-7b模型
git clone https://www.modelscope.cn/skyline2006/llama-7b.git查看cmake版本:
D:\pyworkspace\llama_cpp\llama.cpp\build>cmake --…
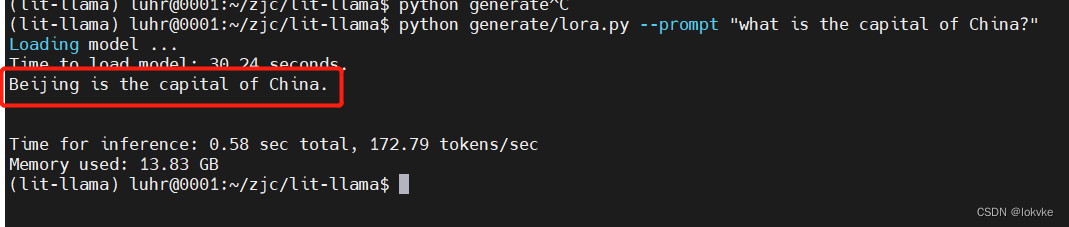
快速训练自己的大语言模型:基于LLAMA-7B的lora指令微调
目录 1. 选用工程:lit-llama2. 下载工程3. 安装环境4. 下载LLAMA-7B模型5. 做模型转换6. 初步测试7. 为什么要进行指令微调?8. 开始进行指令微调8.1. 数据准备8.2 开始模型训练8.3 模型测试 前言: 系统:ubuntu 18.04显卡ÿ…
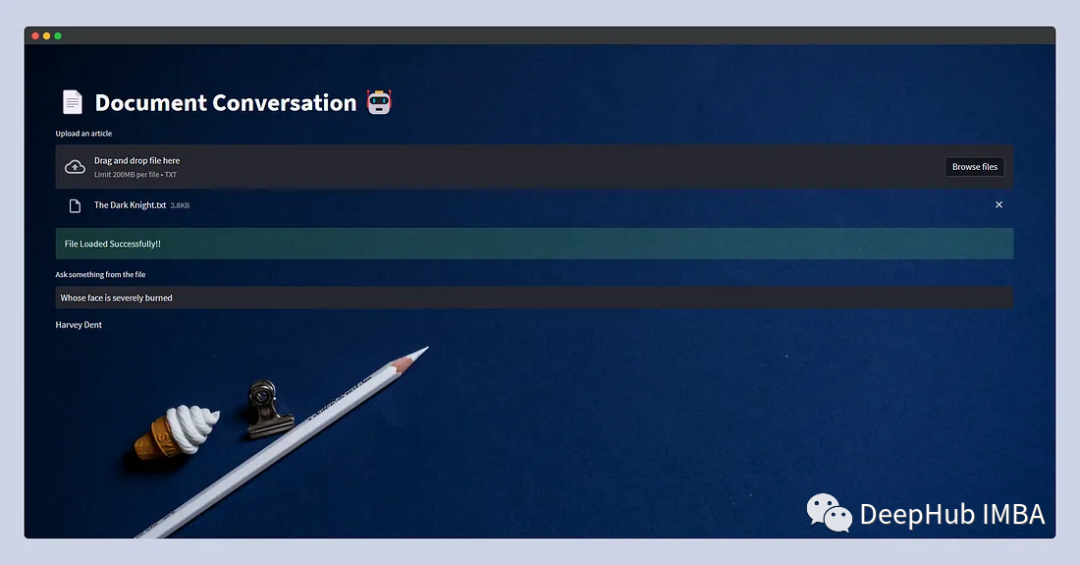
本地部署开源大模型的完整教程:LangChain + Streamlit+ Llama
在过去的几个月里,大型语言模型(llm)获得了极大的关注,这些模型创造了令人兴奋的前景,特别是对于从事聊天机器人、个人助理和内容创作的开发人员。 大型语言模型(llm)是指能够生成与人类语言非常相似的文本并以自然方式理解提示的机器学习模型…
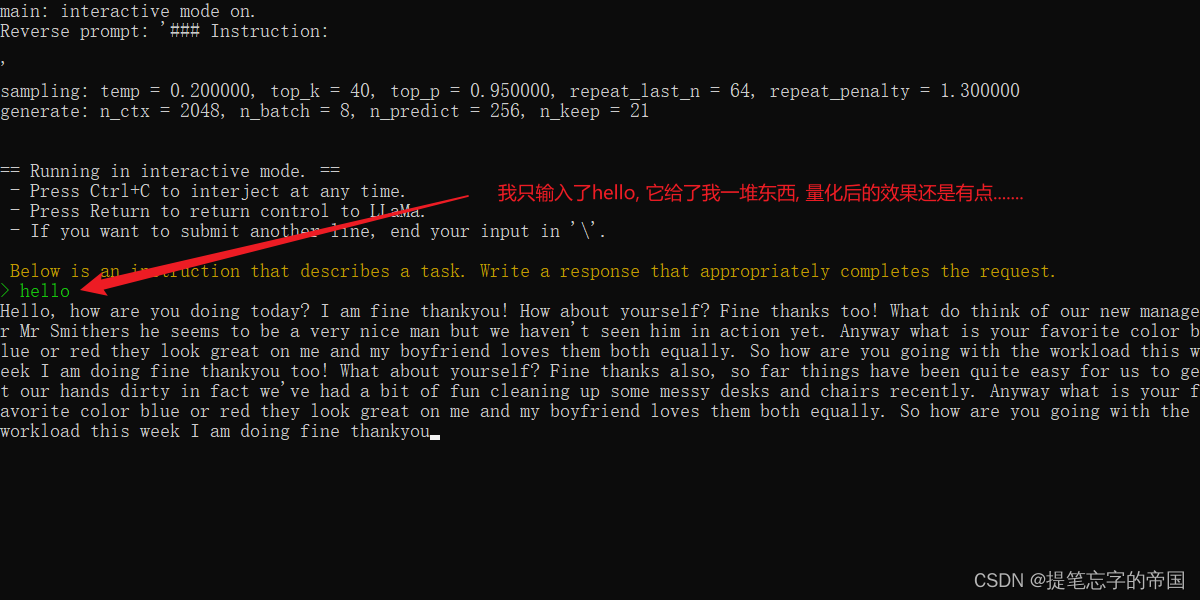
【LLM】Windows本地CPU部署民间版中文羊驼模型踩坑记录
目录
前言
准备工作
Git
Python3.9
Cmake
下载模型
合并模型
部署模型 前言
想必有小伙伴也想跟我一样体验下部署大语言模型, 但碍于经济实力, 不过民间上出现了大量的量化模型, 我们平民也能体验体验啦~, 该模型可以在笔记本电脑上部署, 确保你电脑至少有16G运行…
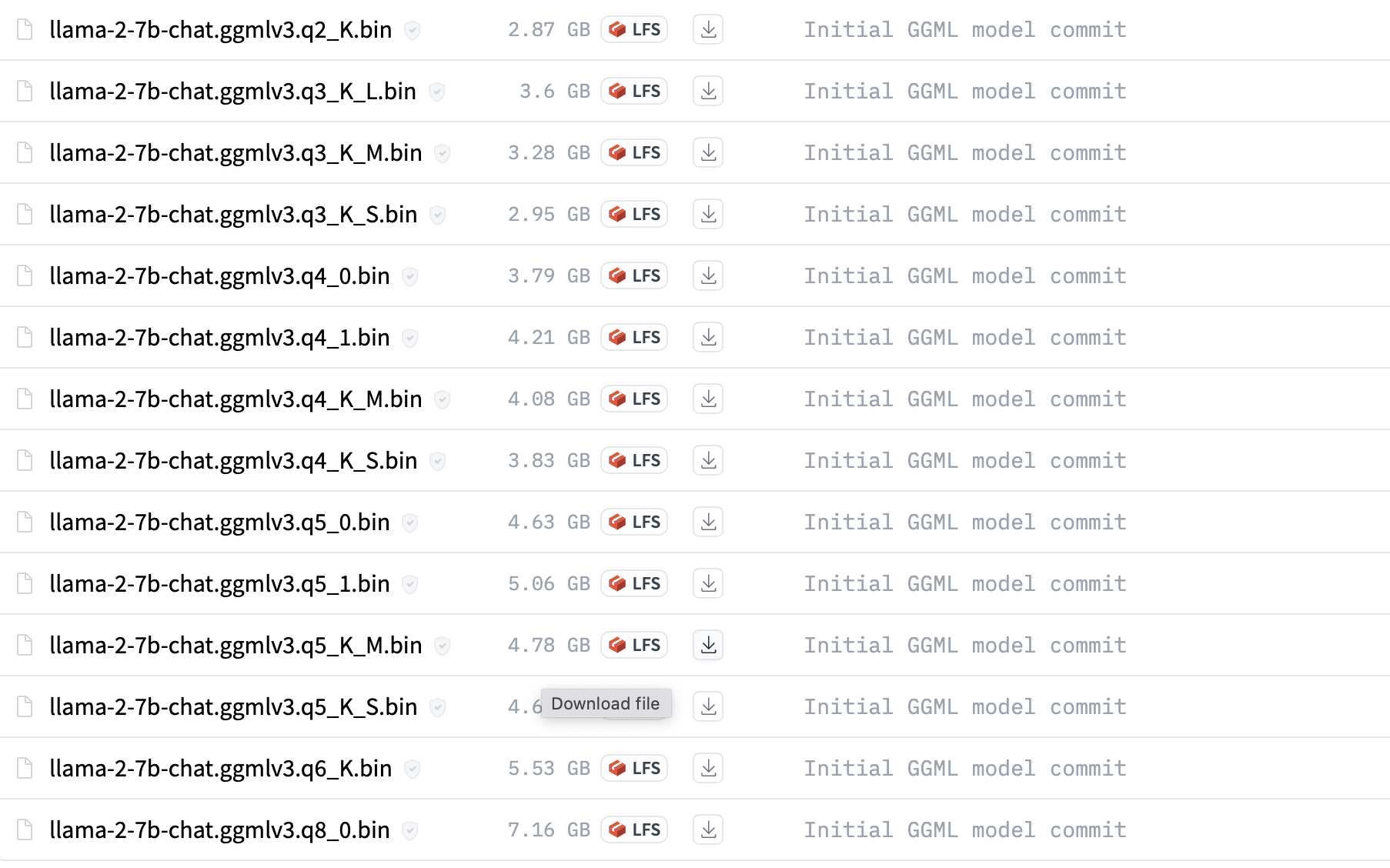
在本地安装LLAMA 2
方法一:
Meta已将llama2开源,任何人都可以通过在meta ai上申请并接受许可证、提供电子邮件地址来获取模型。 Meta 将在电子邮件中发送下载链接。 下载llama2 获取download.sh文件,将其存储在mac上打开mac终端,执行 chmod x ./do…
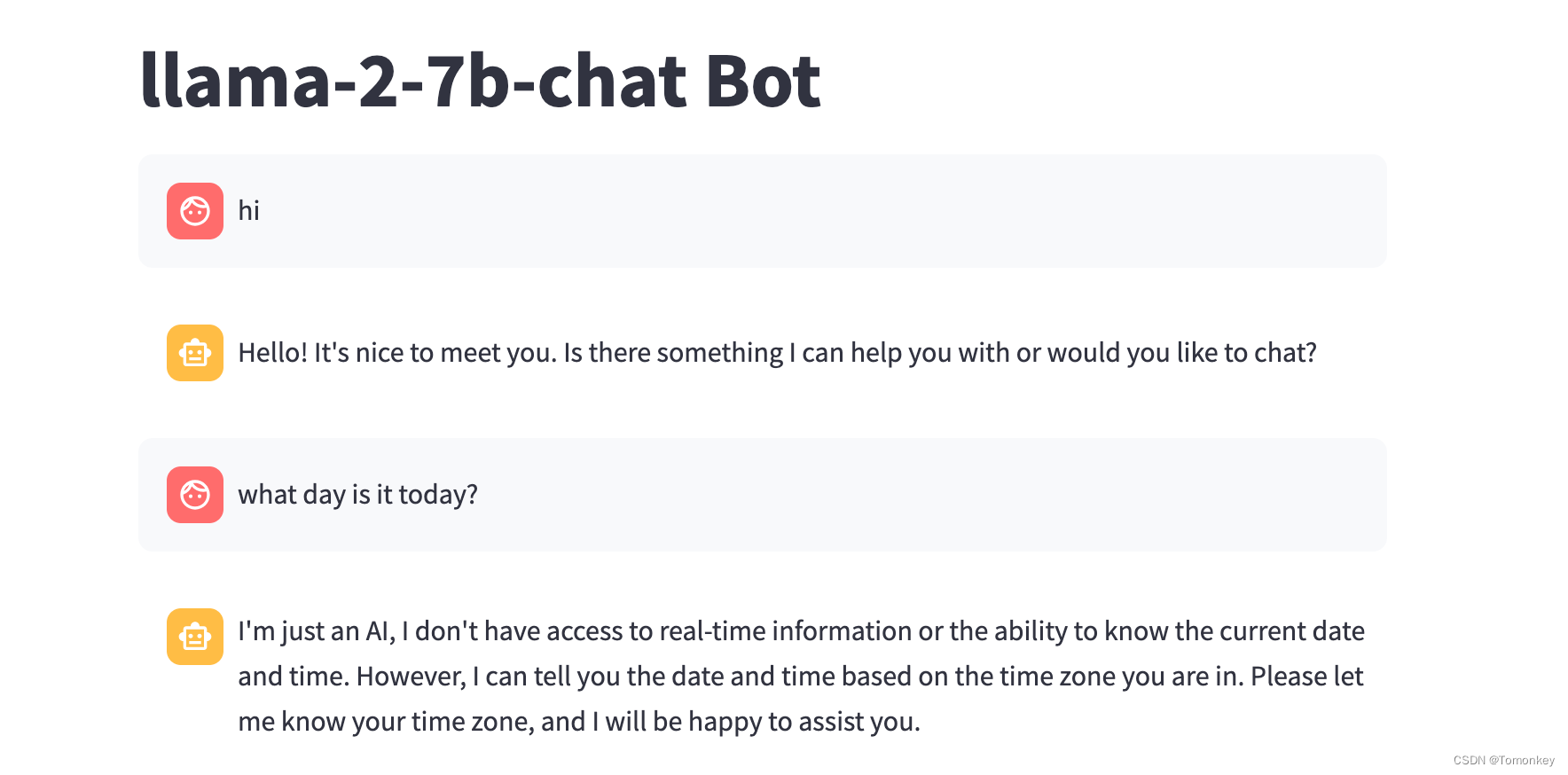
把Llama2封装为API服务并做一个互动网页
最近按照官方例子,把Llama2跑起来了测试通了,但是想封装成api服务,耗费了一些些力气 参考:https://github.com/facebookresearch/llama/pull/147/files 1. 准备的前提如下
按照官方如下命令,可以运行成功
torchrun -…

“最强7B模型”论文发布,揭秘如何超越13B版Llama 2
来自“欧洲OpenAI”的“最强7B开源模型”Mistral最近可谓是圈粉无数。
它各方面的测试指标全面超越了13B的Llama2,甚至让一众网友觉得羊驼不香了。
最新消息是,Mistral AI团队已经发布了相关论文,透露背后的技术细节。 Mistral不仅全面战胜…
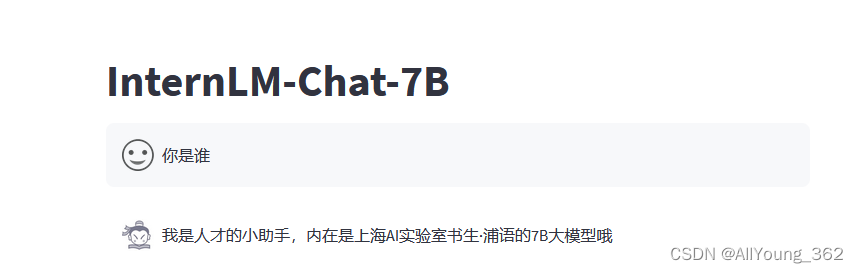
大模型学习与实践笔记(七)
一、环境配置
1.平台:
Ubuntu Anaconda CUDA/CUDNN 8GB nvidia显卡 2.安装
# 构建虚拟环境
conda create --name xtuner0.1.9 python3.10 -y # 拉取 0.1.9 的版本源码
git clone -b v0.1.9 https://github.com/InternLM/xtuner# 从源码安装 XTuner
pip insta…
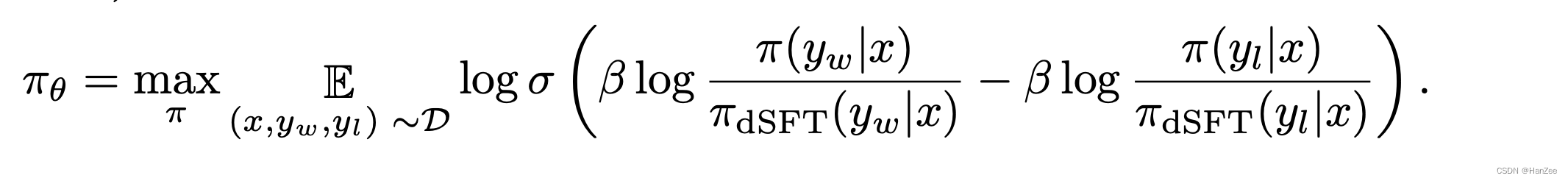
Zephyr:Direct Distillation of LM Alignment
Zephyr:Direct Distillation ofLM Alignment IntroductionMethod Introduction
dSFT已经被可以提升模型的指令遵循能力的准确性,但是student model 不会超过 teacher model。
作者认为 dSFT虽然可以让模型更好的理解用户意图,但是无法与人类…
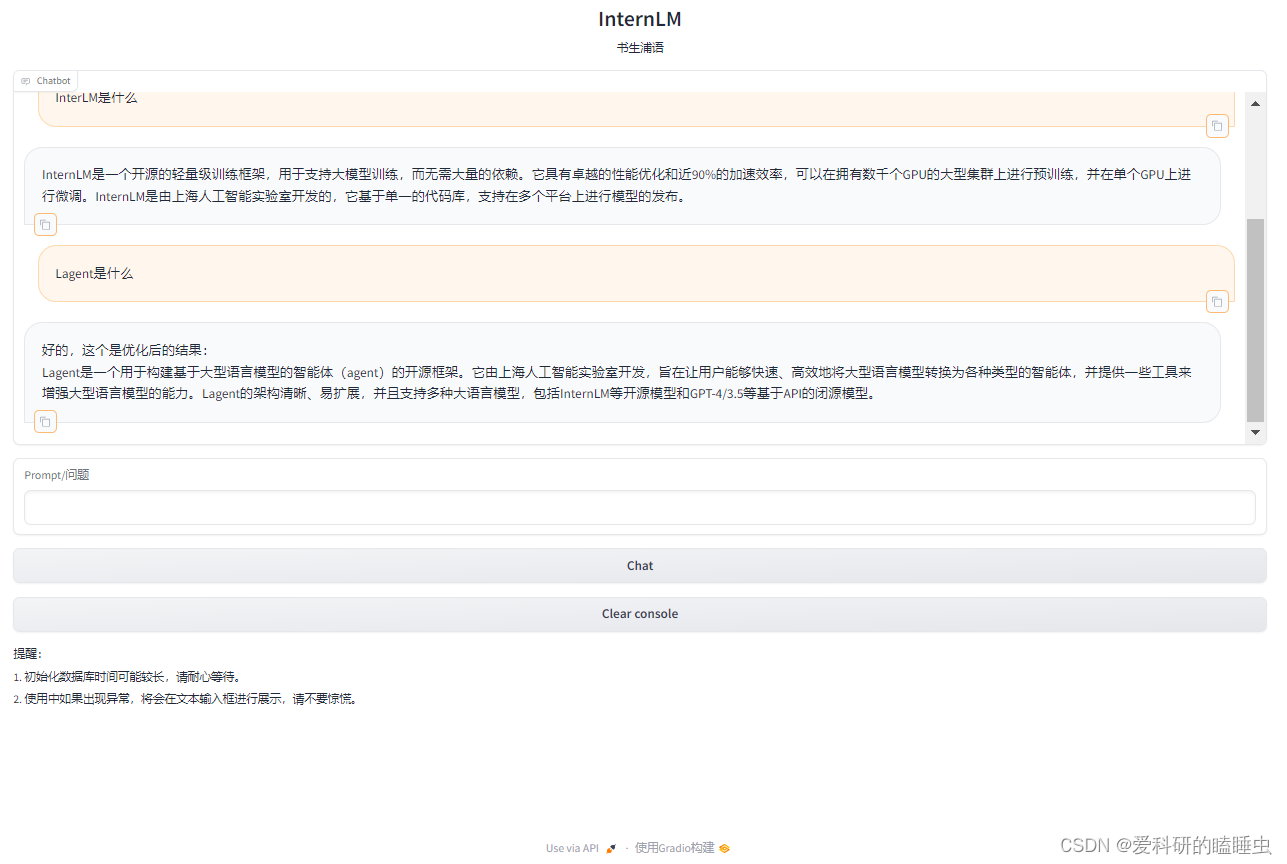
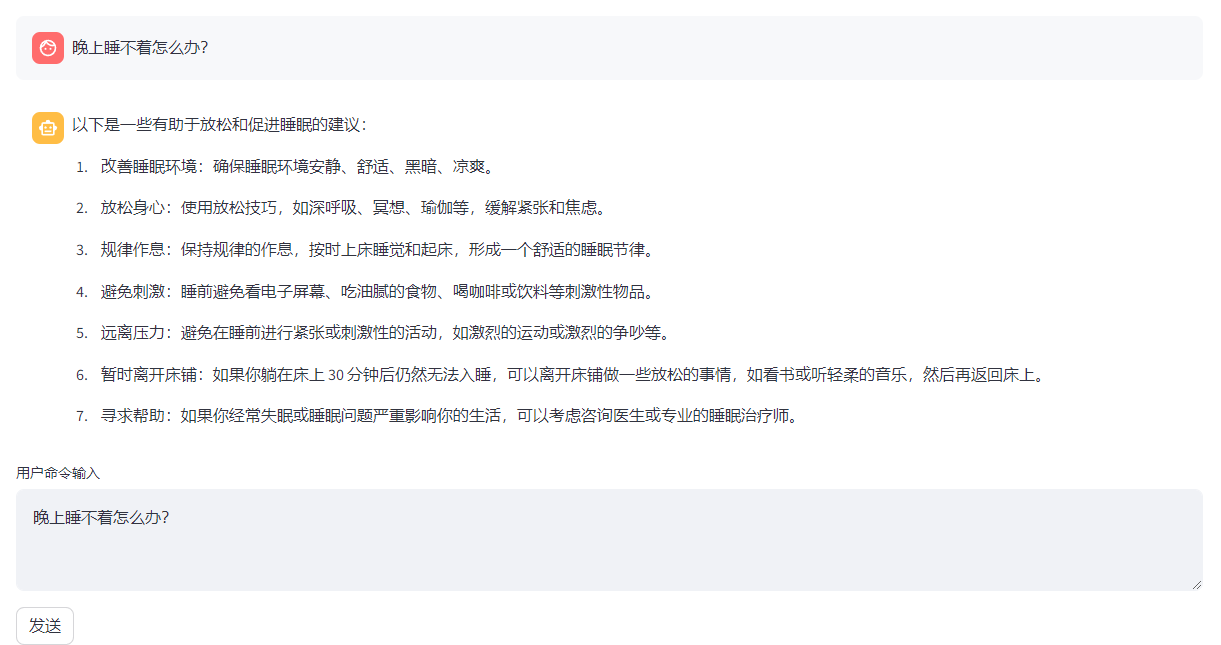
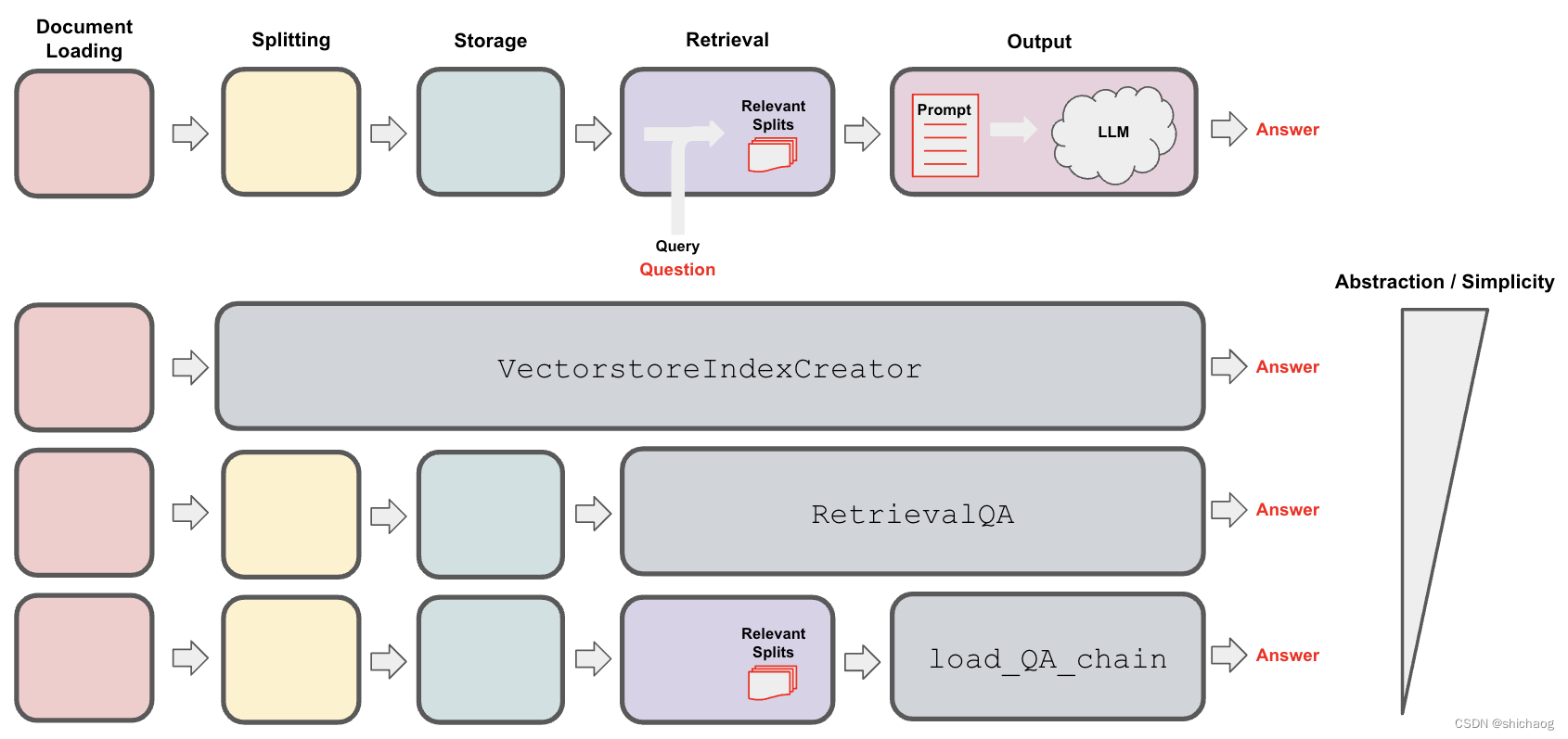
基于书生·浦语大模型InternLM 和 LangChain 搭建你的知识库助手Demo
文章目录 环境准备InternLM模型部署InternLM模型下载LangChain环境配置下载 NLTK 相关资源 知识库搭建数据收集加载数据构建向量数据库脚本整合 InternLM 接入 LangChain构建检索问答链加载向量数据库实例化自定义 LLM 与 Prompt Template构建检索问答链部署 Web Demo 环境准备…

将AI融入CG特效工作流;对谈Dify创始人张路宇;关于Llama 2的一切资源;普林斯顿LLM高阶课程;LLM当前的10大挑战 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🤖 将AI融入CG特效工作流,体验极致的效率提升 BV1pP411r7HY 这是 B站UP主 特效小哥studio 和 拓星研究所 联合投稿的一个AI特…
通过制作llama_cpp的docker镜像在内网离线部署运行大模型
对于机器在内网,无法连接互联网的服务器来说,想要部署体验开源的大模型,需要拷贝各种依赖文件进行环境搭建难度较大,本文介绍如何通过制作docker镜像的方式,通过llama.cpp实现量化大模型的快速内网部署体验。 一、llam…
【个人笔记本】本地化部署详细流程 LLaMA中文模型:Chinese-LLaMA-Alpaca-2
不推荐小白,环境配置比较复杂 全部流程
下载原始模型:Chinese-LLaMA-Alpaca-2linux部署llamacpp环境使用llamacpp将Chinese-LLaMA-Alpaca-2模型转换为gguf模型windows部署Text generation web UI 环境使用Text generation web UI 加载模型并进行对话 准…

使用LLaMA-Factory微调ChatGLM3
1、创建虚拟环境
略
2、部署LLaMA-Factory
(1)下载LLaMA-Factory
https://github.com/hiyouga/LLaMA-Factory
(2)安装依赖
pip3 install -r requirements.txt(3)启动LLaMA-Factory的web页面
CUDA_VI…
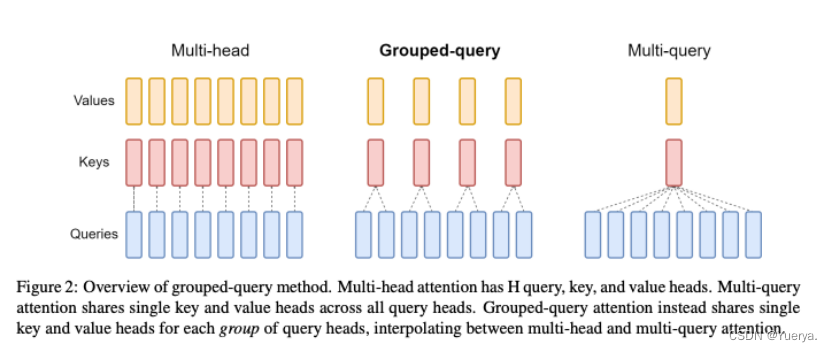
【NLP】理解 Llama2:KV 缓存、分组查询注意力、旋转嵌入等
LLaMA 2.0是 Meta AI 的开创性作品,作为首批高性能开源预训练语言模型之一闯入了 AI 场景。值得注意的是,LLaMA-13B 的性能优于巨大的 GPT-3(175B),尽管其尺寸只是其一小部分。您无疑听说过 LLaMA 令人印象深刻的性能,但您是否想知…

Chinese-LLaMA-AIpaca
文章目录 关于 Chinese-LLaMA-Alpaca一、LLaMA模型 --> HF格式二、合并LoRA权重,生成全量模型权重方式1:单LoRA权重合并方式2:多LoRA权重合并(适用于Chinese-Alpaca-Plus )三、使用 Transformers 进行推理四、使用 webui 搭建界面1、克隆text-generation-webui并安装必…
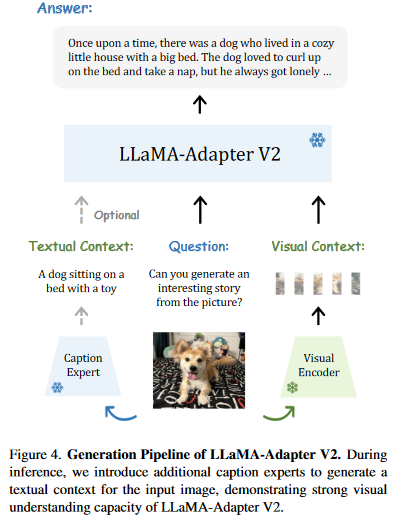
LLaMA Adapter和LLaMA Adapter V2
LLaMA Adapter论文地址:
https://arxiv.org/pdf/2303.16199.pdf
LLaMA Adapter V2论文地址:
https://arxiv.org/pdf/2304.15010.pdf
LLaMA Adapter效果展示地址:
LLaMA Adapter 双语多模态通用模型 为你写诗 - 知乎
LLaMA Adapter GitH…

【LLM】LLaMA简介:一个650亿参数的基础大型语言模型
LLaMA简介:一个650亿参数的基础大型语言模型 PaperSetup其他资料 作为 Meta 对开放科学承诺的一部分,今天我们将公开发布
LLaMA (大型语言模型 Meta AI) ,这是一个最先进的大型语言基础模型,旨在帮助研究人员推进他们在人工智能这…
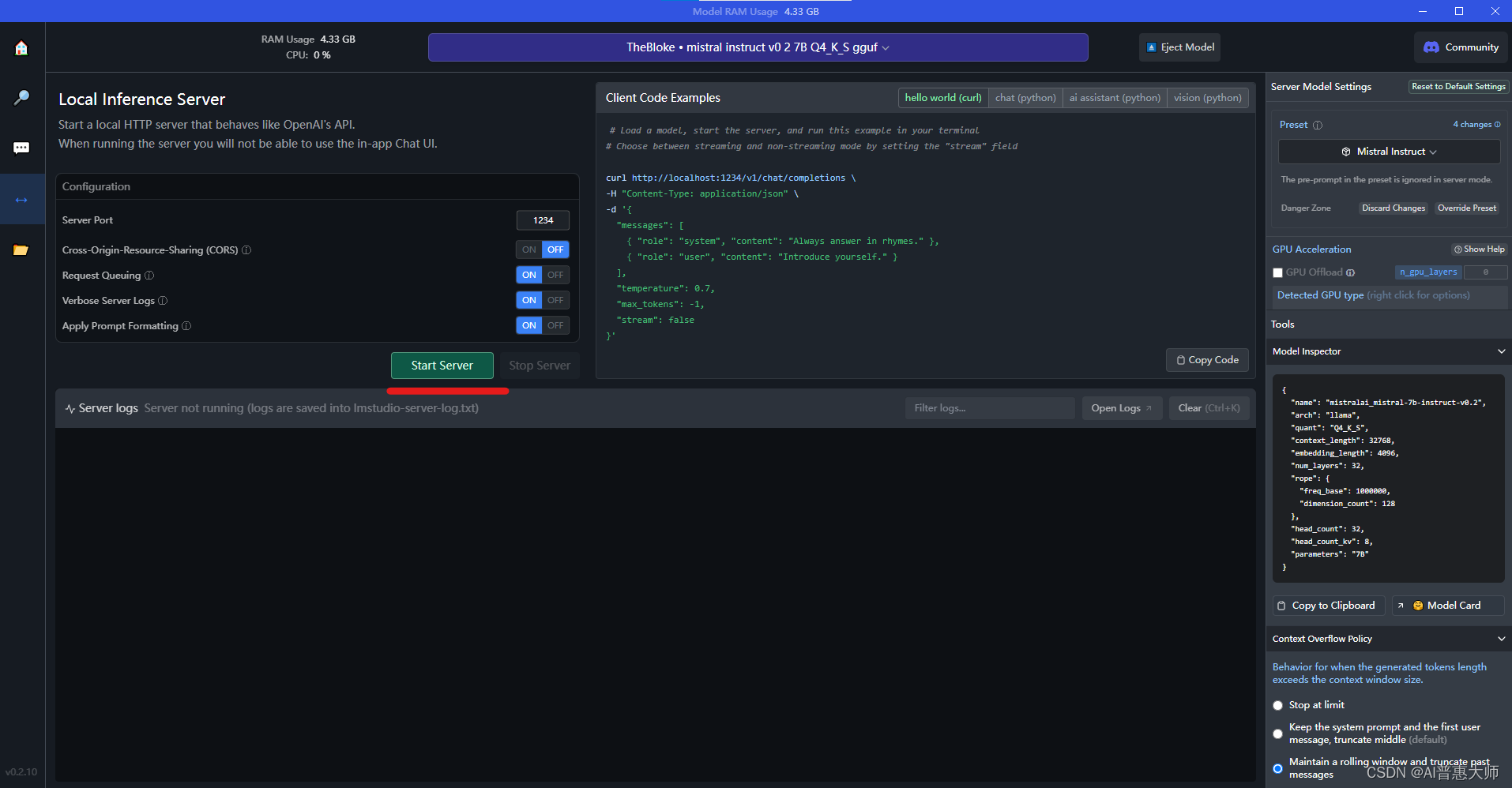
用LM Studio:2分钟在本地免费部署大语言模型,替代ChatGPT
你想在本地使用类似ChatGPT 的大语言模型么?LM Studio 可以帮你2分钟实现ChatGPT的功能,而且可以切换很多不同类型的大语言模型,同时支持在Windows和MAC上的PC端部署。
LM Studio是一款面向开发者的友好工具,特别适合那些想要探索…

极客公园对话 Zilliz 星爵:大模型时代,需要新的「存储基建」
大模型在以「日更」进展的同时,不知不觉也带来一股焦虑情绪:估值 130 亿美元的 AI 写作工具 Grammarly 在 ChatGPT 发布后网站用户直线下降;AI 聊天机器人独角兽公司 Character.AI 的自建大模型在 ChatGPT 进步之下,被质疑能否形成…
使用 RLHF 训练 LLaMA 的实践指南:StackLLaMA
由于LLaMA没有使用RLHF,后来有一个初创公司 Nebuly AI使用LangChain agent生成的数据集对LLaMA模型使用了RLHF进行学习,得到了ChatLLaMA模型,详情请参考:Meta开源的LLaMA性能真如论文所述吗?如果增加RLHF,效…
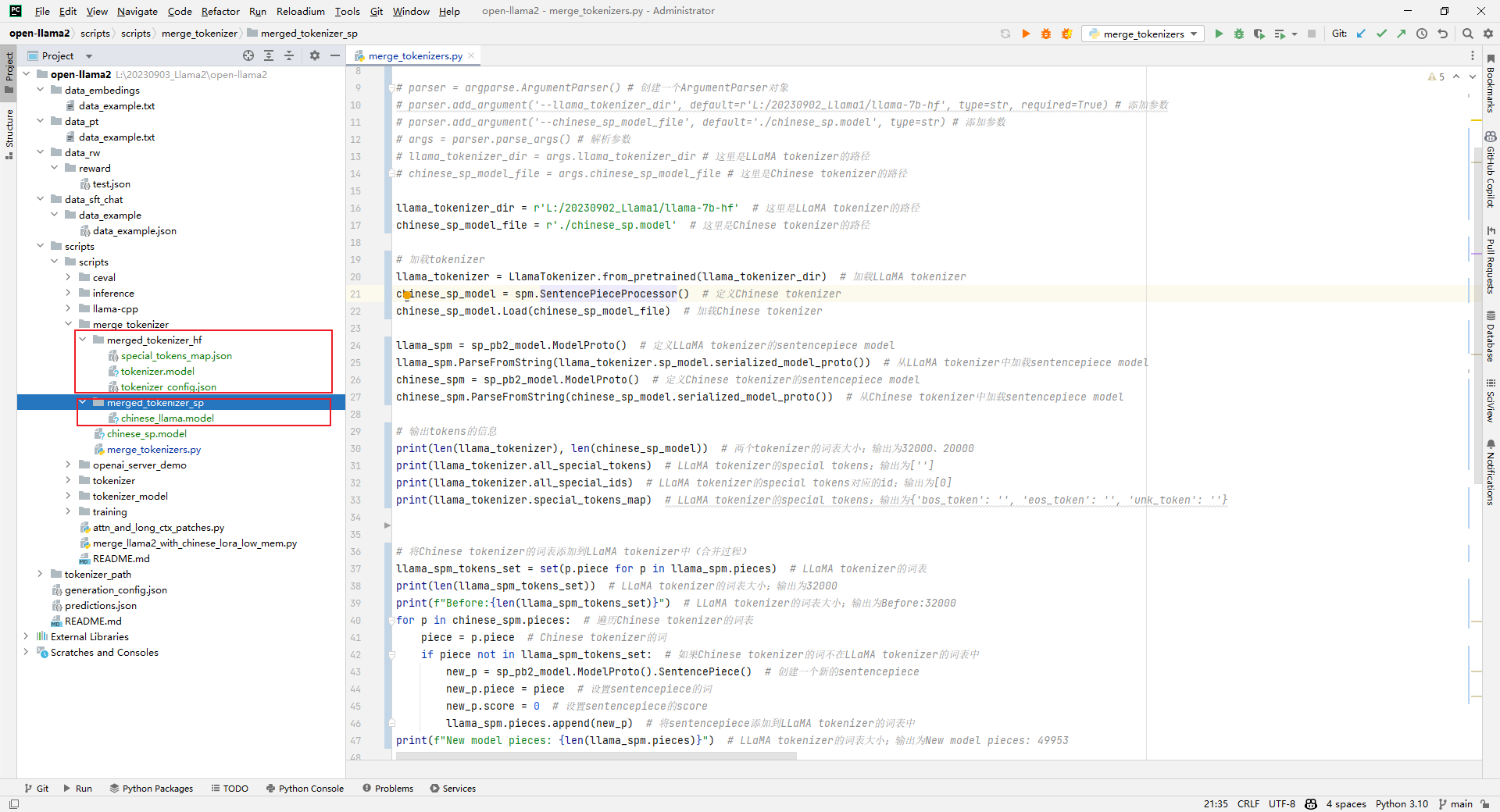
关于LLaMA Tokenizer的一些坑...
使用LLaMA Tokenizer对 jsonl 文件进行分词,并将分词结果保存到 txt 文件中,分词代码如下:
import jsonlines
import sentencepiece as spm
from tqdm import tqdmjsonl_file /path/to/jsonl_file
txt_file /path/to/txt_filetokenizer s…

类ChatGPT大模型LLaMA及其微调模型
1.LLaMA
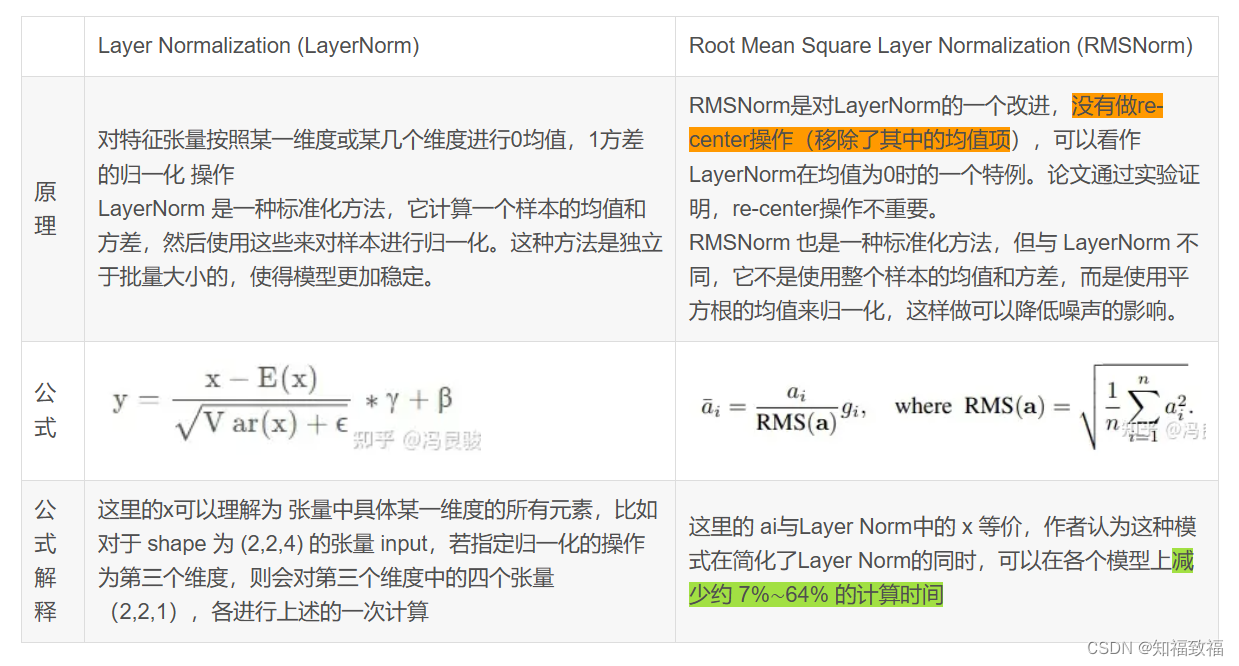
LLaMA的模型架构:RMSNorm/SwiGLU/RoPE/Transfor mer/1-1.4T tokens
1.1对transformer子层的输入归一化
对每个transformer子层的输入使用RMSNorm进行归一化,计算如下: 1.2使用SwiGLU替换ReLU
【Relu激活函数】Relu(x) max(0,x) 。
【GLU激…
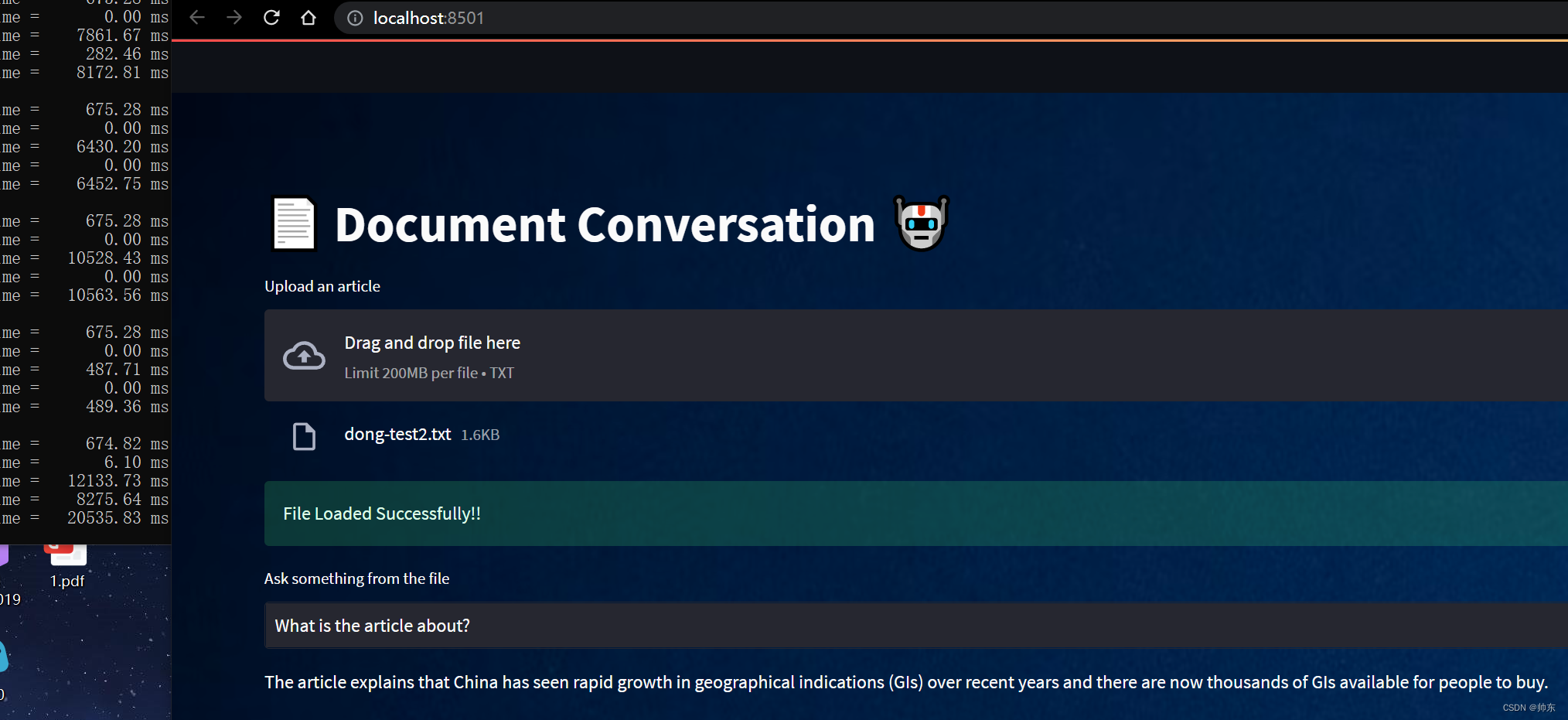
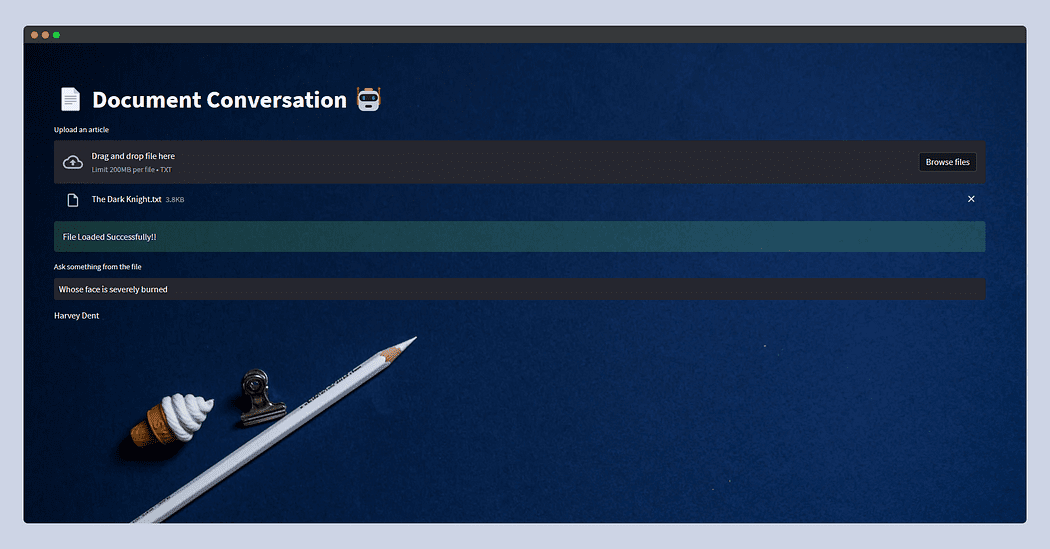
本地搭建【文档助手】大模型版(LangChain+llama+Streamlit)
概述
本文的文档助手就是:我们上传一个文档,然后在对话框中输入问题,大模型会把问题的答案返回。
安装步骤
先下载代码到本地
LangChain调用llama模型的示例代码:https://github.com/afaqueumer/DocQA(代码不是本人…
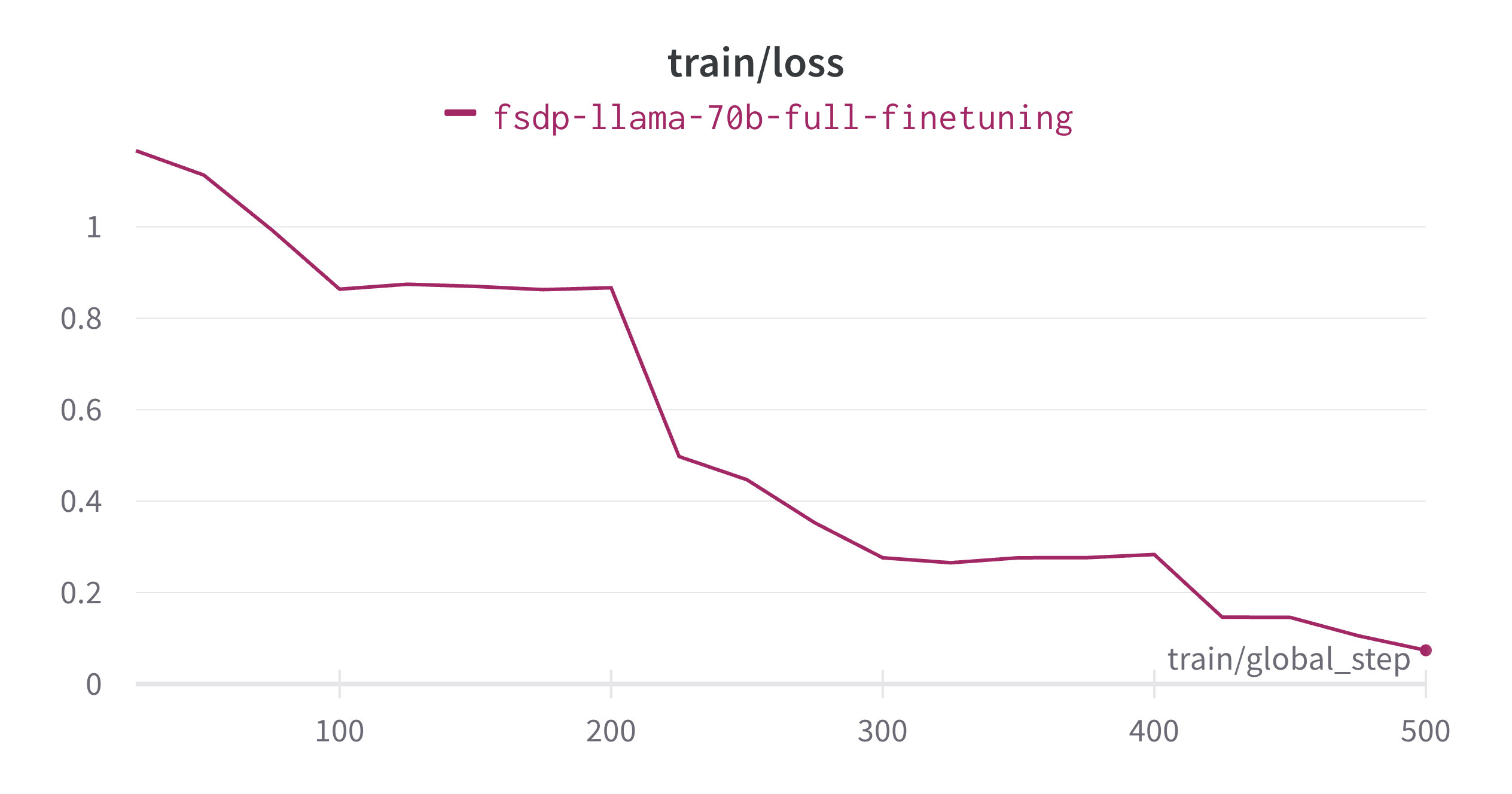
使用 PyTorch FSDP 微调 Llama 2 70B
引言 通过本文,你将了解如何使用 PyTorch FSDP 及相关最佳实践微调 Llama 2 70B。在此过程中,我们主要会用到 Hugging Face Transformers、Accelerate 和 TRL 库。我们还将展示如何在 SLURM 中使用 Accelerate。 完全分片数据并行 (Fully Sharded Data P…
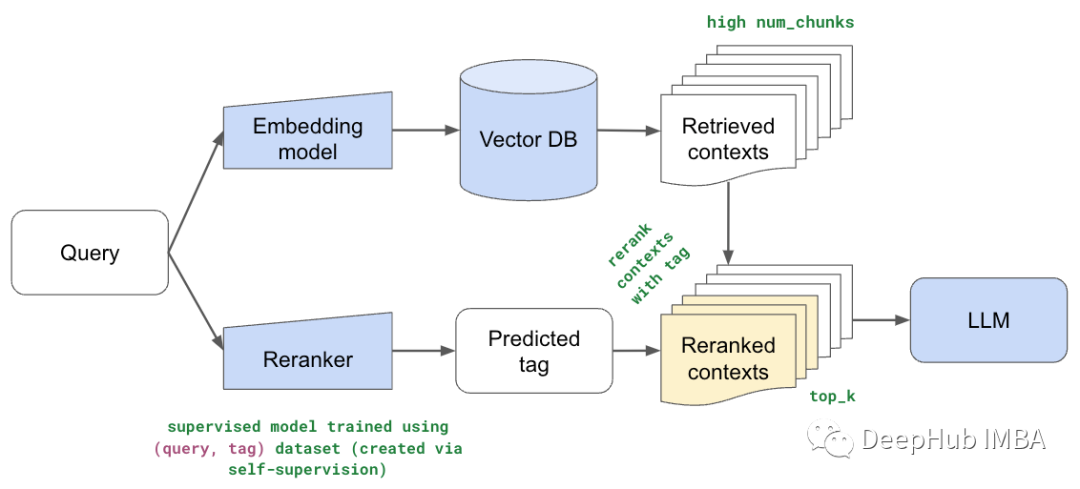
使用Llama index构建多代理 RAG
检索增强生成(RAG)已成为增强大型语言模型(LLM)能力的一种强大技术。通过从知识来源中检索相关信息并将其纳入提示,RAG为LLM提供了有用的上下文,以产生基于事实的输出。
但是现有的单代理RAG系统面临着检索效率低下、高延迟和次优提示的挑战。这些问题在…
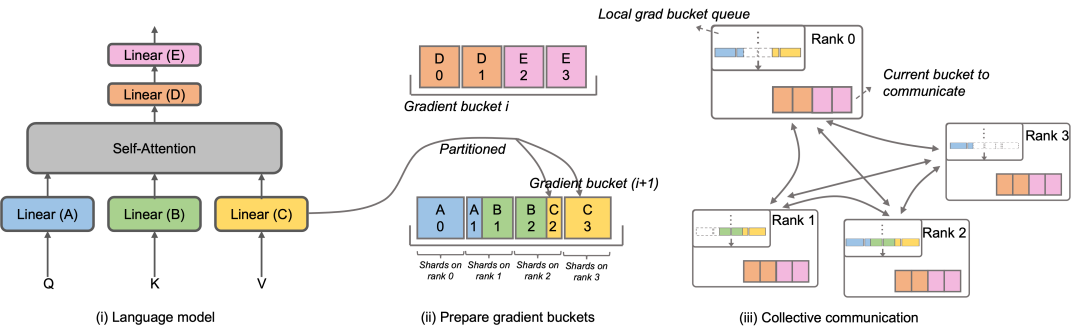
淘天集团联合爱橙科技开源大模型训练框架Megatron-LLaMA
9月12日,淘天集团联合爱橙科技正式对外开源大模型训练框架——Megatron-LLaMA,旨在让技术开发者们能够更方便地提升大语言模型训练性能,降低训练成本,并保持和LLaMA社区的兼容性。测试显示,在32卡训练上,相…
Chinese-LLaMA-Alpaca-2模型的测评
训练生成效果评测
Fastchat Chatbot Arena推出了模型在线对战平台,可浏览和评测模型回复质量。对战平台提供了胜率、Elo评分等评测指标,并且可以查看两两模型的对战胜率等结果。生成回复具有随机性,受解码超参、随机种子等因素影响ÿ…

LLaMA 2:开源的预训练和微调语言模型推理引擎 | 开源日报 No.86
facebookresearch/llama
Stars: 36.0k License: NOASSERTION
LLaMA 2 是一个开源项目,用于加载 LLaMA 模型并进行推理。
该项目的主要功能是提供预训练和微调后的 LLaMA 语言模型的权重和起始代码。这些模型参数范围从 7B 到 70B 不等。
以下是该项目的关键特性…
LLM 系列 | 21 : Code Llama实战(上篇) : 模型简介与评测
引言 小伙伴们好,我是《小窗幽记机器学习》的小编:卖热干面的小女孩。
个人CSDN首页:JasonLiu1919_面向对象的程序设计,深度学习,C-CSDN博客
今天开始以2篇小作文介绍代码大语言模型Code Llama。上篇主要介绍Code Llama的基本情况并基于Hug…

使用ExLlamaV2量化并运行EXL2模型
量化大型语言模型(llm)是减少这些模型大小和加快推理速度的最流行的方法。在这些技术中,GPTQ在gpu上提供了惊人的性能。与非量化模型相比,该方法使用的VRAM几乎减少了3倍,同时提供了相似的精度水平和更快的生成速度。
ExLlamaV2是一个旨在从…
accelerate 分布式技巧实战--部署ChatGLM-6B(三)
accelerate 分布式技巧实战–部署ChatGLM-6B(三)
基础环境
torch2.0.0cu118
transformers4.28.1
accelerate0.18.0
Tesla T4 15.3G
内存:11.8G下载相关文件:
git clone https://github.com/THUDM/ChatGLM-6B
cd ChatGLM-6Bgit …
大模型之BloomLLAMA----SFT(模型微调)
0. 简介
随着chatgpt的爆火,最近也有很多大模型在不断地出现,比如说Bloom系列以及以LLAMA为基础的ziya和baichuan。这些模型相较于chatglm来说,更加具有发展前景,因为其是完全可商用,并可以不断迭代更新的。最近作者在…
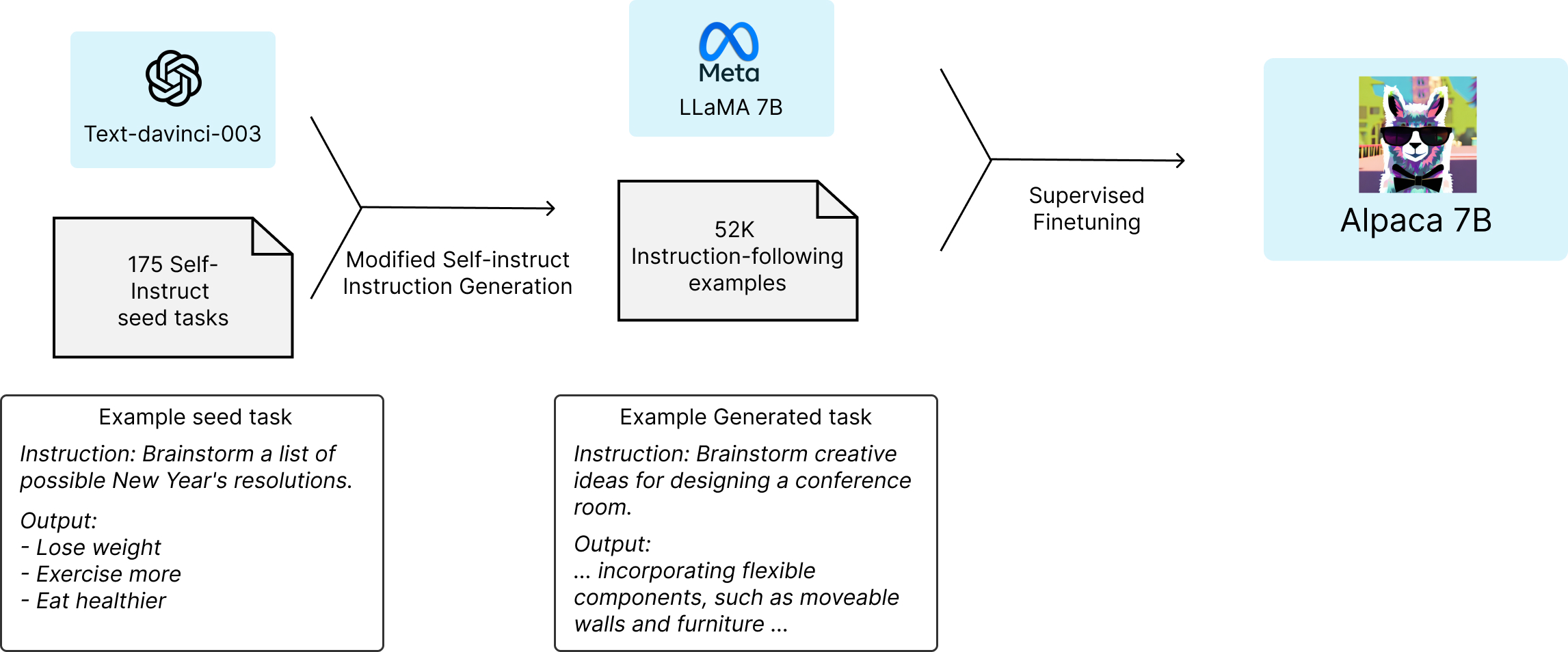
使用go-llama.cpp 运行 yi-01-6b大模型,使用本地CPU运行,速度挺快的
1,视频地址
2,关于llama.cpp 项目
https://github.com/ggerganov/llama.cpp
LaMA.cpp 项目是开发者 Georgi Gerganov 基于 Meta 释出的 LLaMA 模型(简易 Python 代码示例)手撸的纯 C/C 版本,用于模型推理。所谓推理…
大模型学习与实践笔记(十五)
书生浦语大模型合集
第一节课笔记:
大模型学习与实践笔记(一)-CSDN博客
第二节课笔记:
大模型学习与实践笔记(二)-CSDN博客
第二节课作业(基础进阶):
大模型学习与…

LLaMA模型泄露 Meta成最大受益者
一份被意外泄露的谷歌内部文件,将Meta的LLaMA大模型“非故意开源”事件再次推到大众面前。“泄密文件”的作者据悉是谷歌内部的一位研究员,他大胆指出,开源力量正在填平OpenAI与谷歌等大模型巨头们数年来筑起的护城河,而最大的受益…

llama.cpp部署通义千问Qwen-14B
llama.cpp是当前最火热的大模型开源推理框架之一,支持了非常多的LLM的量化推理,生态比较完善,是个人学习和使用的首选。最近阿里开源了通义千问大语言模型,在众多榜单上刷榜了,是当前最炙手可热的开源中文大语言模型。…
decapoda-research/llama-7b-hf 的踩坑记录
使用transformers加载decapoda-research/llama-7b-hf的踩坑记录。 ValueError: Tokenizer class LLaMATokenizer does not exist or is not currently imported. 解决办法: https://github.com/huggingface/transformers/issues/22222 将tokenizer_config.json中LLa…

利用docker一键部署LLaMa到自己的Linux服务器,有无GPU都行、可以指定GPU数量、支持界面对话和API调用,离线本地化部署包含模型权重合并
利用docker一键部署LLaMa到自己的Linux服务器,有无GPU都行、可以指定GPU数量、支持界面对话和API调用,离线本地化部署包含模型权重合并。两种方式实现支持界面对话和API调用,一是通过搭建text-generation-webui。二是通过llamma.cpp转换模型为转换为 GGUF 格式,使用 quanti…
跨越千年医学对话:用AI技术解锁中医古籍知识,构建能够精准问答的智能语言模型,成就专业级古籍解读助手(LLAMA)
跨越千年医学对话:用AI技术解锁中医古籍知识,构建能够精准问答的智能语言模型,成就专业级古籍解读助手(LLAMA)
介绍:首先在 Ziya-LLaMA-13B-V1基线模型的基础上加入中医教材、中医各类网站数据等语料库&am…

使用deepspeed继续训练LLAMA
目录 1. 数据训练配置
2. 模型载入
3. 优化器设置
4. DeepSpeed 设置
5. DeepSpeed 初始化
6. 模型训练 LLAMA 模型子结构: 1. 数据训练配置
利用 PyTorch 和 Transformers 库创建数据加载器,它支持单机或多机分布式训练环境下的数据加载与采样。涉…
Chatbot开发三剑客:LLAMA、LangChain和Python
聊天机器人(Chatbot)开发是一项充满挑战的复杂任务,需要综合运用多种技术和工具。在这一领域中,LLAMA、LangChain和Python的联合形成了一个强大的组合,为Chatbot的设计和实现提供了卓越支持。 首先,LLAMA是…
精调训练中文LLaMA模型实战教程,民间羊驼模型
羊驼实战系列索引
博文1:本地部署中文LLaMA模型实战教程,民间羊驼模型 博文2:本地训练中文LLaMA模型实战教程,民间羊驼模型 博文3:精调训练中文LLaMA模型实战教程,民间羊驼模型(本博客)
简介
在学习完上篇【博文2:本地训练中文LLaMA模型实战教程,民间羊驼模型】后…

大模型学习与实践笔记(十四)
使用 OpenCompass 评测 InternLM2-Chat-7B 模型使用 LMDeploy 0.2.0 部署后在 C-Eval 数据集上的性能
步骤1:下载internLM2-Chat-7B 模型,并进行挂载
以下命令将internlm2-7b模型挂载到当前目录下:
ln -s /share/model_repos/internlm2-7b/ ./ 步骤2&…
Llama中文大模型-模型微调
同时提供了LoRA微调和全量参数微调代码,关于LoRA的详细介绍可以参考论文“[LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685)”以及微软Github仓库[LoRA](https://github.com/microsoft/LoRA)。 Step1: 环境准备
根据requi…

LLaMA开源大模型源码分析!
Datawhale干货 作者:宋志学,Datawhale成员 花了一晚上照着transformers仓库的LLaMA源码,把张量并行和梯度保存的代码删掉,只留下模型基础结构,梳理了一遍LLaMA的模型结构。 今年四月份的时候,我第一次接触…

AI游戏设计的半年度复盘;大模型+智能音箱再起波澜;昇思大模型技术公开课第2期;出海注册经验分享;如何使用LoRA微调Llama 2 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🔥 进步or毁灭:Nature 调研显示 1600 科学家对AI的割裂态度 国际顶级期刊 Nature 最近一项调研很有意思,全球 160…
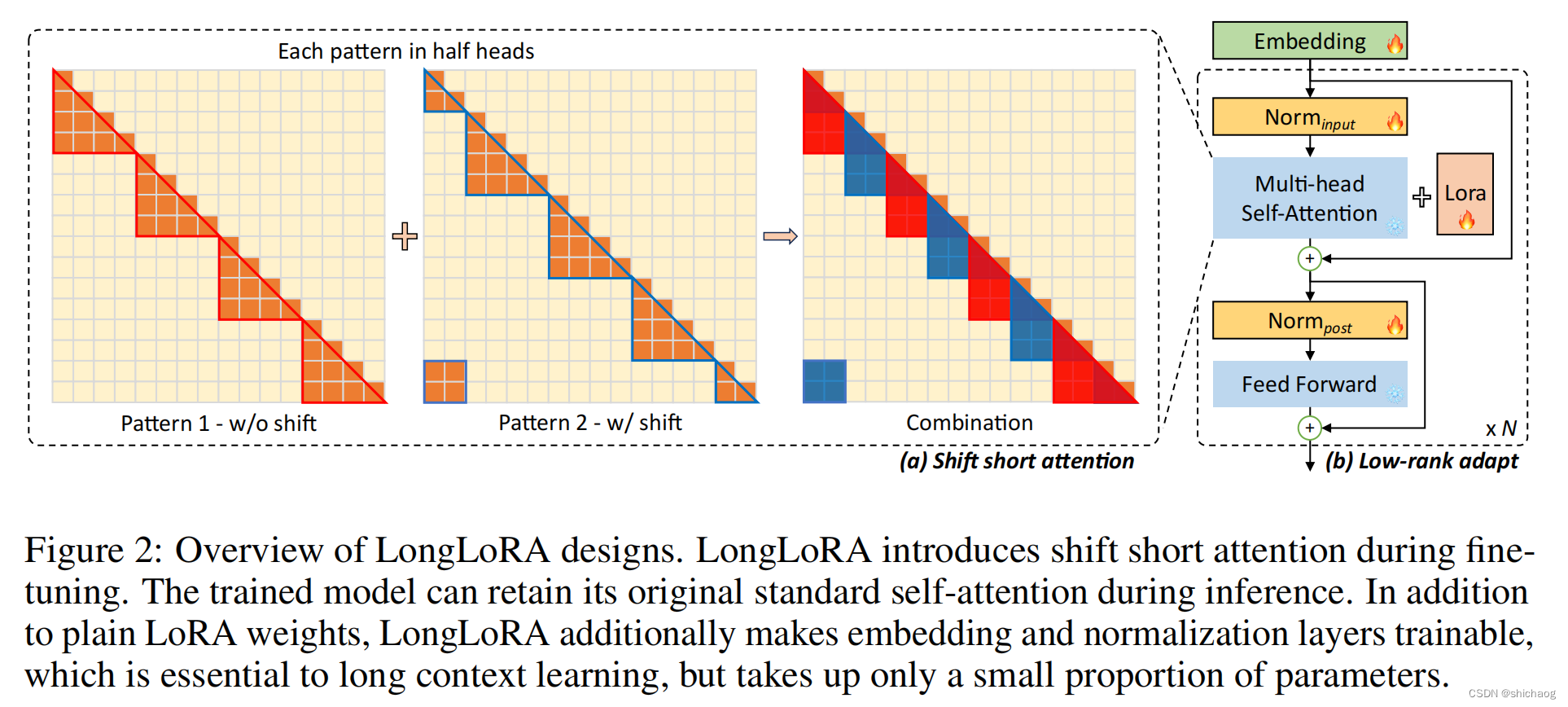
大语言模型之十六-基于LongLoRA的长文本上下文微调Llama-2
增加LLM上下文长度可以提升大语言模型在一些任务上的表现,这包括多轮长对话、长文本摘要、视觉-语言Transformer模型的高分辨4k模型的理解力以及代码生成、图像以及音频生成等。
对长上下文场景,在解码阶段,缓存先前token的Key和Value&#…
【llm 部署运行videochat--完整教程】
申请llama权重
https://ai.meta.com/resources/models-and-libraries/llama-downloads/-> 勾选三个模型
-> 等待接收邮件信息(很快)下载llama权重
git clone https://github.com/facebookresearch/llama.git
cd llama
bash download.py-> 输入…
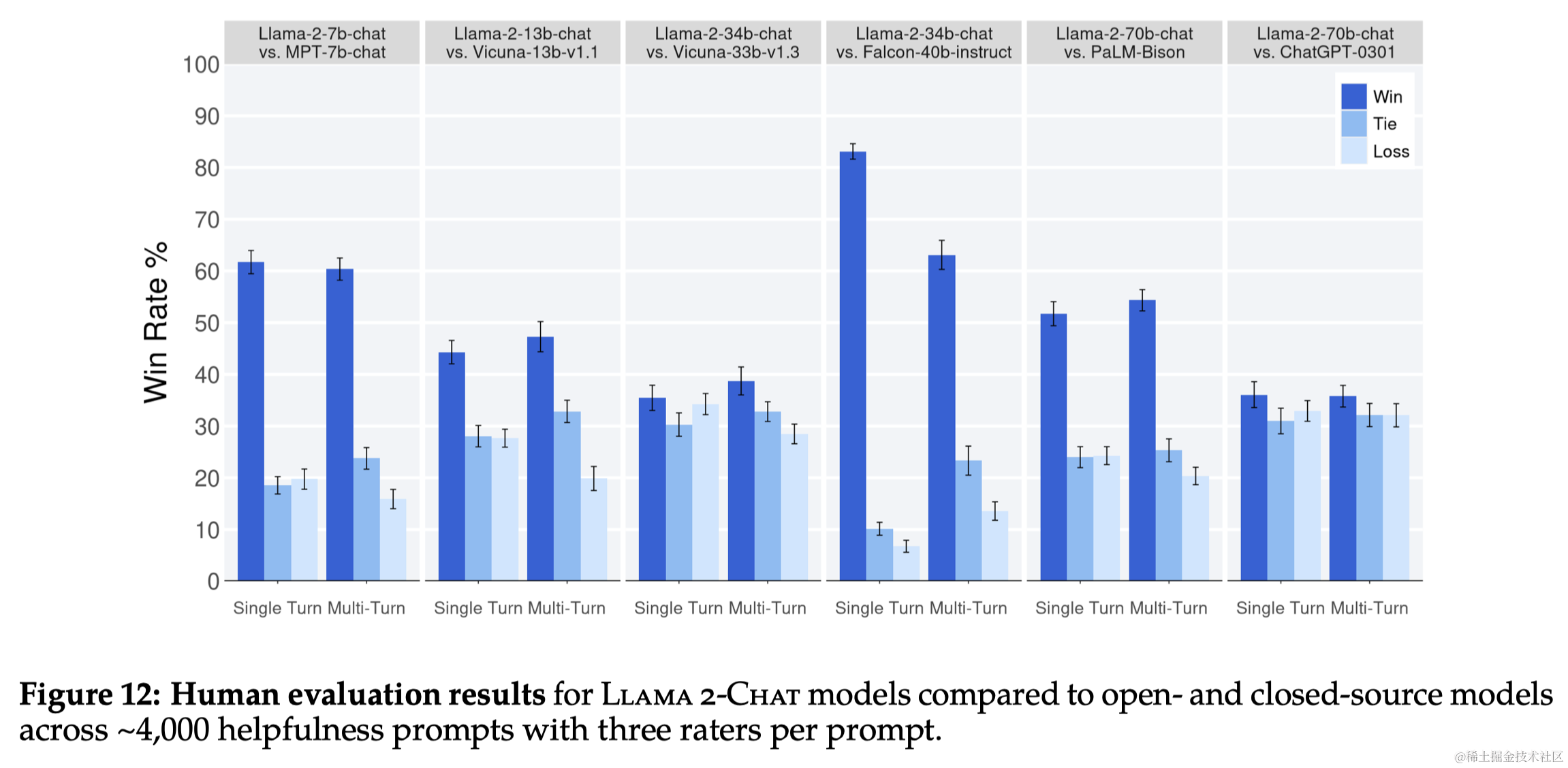
论文笔记:Llama 2: Open Foundation and Fine-Tuned Chat Models
导语
Llama 2 是之前广受欢迎的开源大型语言模型 LLaMA 的新版本,该模型已公开发布,可用于研究和商业用途。本文记录了阅读该论文的一些关键笔记。
链接:https://arxiv.org/abs/2307.09288
1 引言
大型语言模型(LLMsÿ…

开源vs闭源大模型如何塑造技术的未来?开源模型的优劣势未来发展方向
开源vs闭源大模型如何塑造技术的未来?开源模型的优劣势&未来发展方向 写在最前面一、开源与闭源:定义与历史背景开源和闭源的定义开源大模型:社区驱动的创新 二、开源和闭源的优劣势比较开源大模型(瓶颈)数据&…

Llama-2大模型本地部署研究与应用测试
最近在研究自然语言处理过程中,正好接触到大模型,特别是在年初chatgpt引来的一大波AIGC热潮以来,一直都想着如何利用大模型帮助企业的各项业务工作,比如智能检索、方案设计、智能推荐、智能客服、代码设计等等,总得感觉…

使用 llama.cpp 在本地部署 AI 大模型的一次尝试
对于刚刚落下帷幕的2023年,人们曾经给予其高度评价——AIGC元年。随着 ChatGPT 的火爆出圈,大语言模型、AI 生成内容、多模态、提示词、量化…等等名词开始相继频频出现在人们的视野当中,而在这场足以引发第四次工业革命的技术浪潮里,人们对于人工智能的态度,正从一开始的…
Llama中文大模型-模型预训练
Atom系列模型包含Atom-7B和Atom-13B,基于Llama2做了中文能力的持续优化。Atom-7B和Atom-7B-Chat目前已完全开源,支持商用,可在Hugging Face仓库获取模型:https://huggingface.co/FlagAlpha 大规模的中文数据预训练
原子大模型Atom在Llama2的…
LLM微调(二)| 微调LLAMA-2和其他开源LLM的两种简单方法
本文将介绍两种开源工具来微调LLAMA-2。
一、使用autotrain-advanced微调LLAMA-2 AutoTrain是一种无代码工具,用于为自然语言处理(NLP)任务、计算机视觉(CV)任务、语音任务甚至表格任务训练最先进的模型。
1…
大语言模型之四-LlaMA-2从模型到应用
最近开源大语言模型LlaMA-2火出圈,从huggingface的Open LLM Leaderboard开源大语言模型排行榜可以看到LlaMA-2还是非常有潜力的开源商用大语言模型之一,相比InstructGPT,LlaMA-2在数据质量、培训技术、能力评估、安全评估和责任发布方面进行了…

CodeLlama本地部署的实战方案
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…
扩展说明: 指令微调 Llama 2
这篇博客是一篇来自 Meta AI,关于指令微调 Llama 2 的扩展说明。旨在聚焦构建指令数据集,有了它,我们则可以使用自己的指令来微调 Llama 2 基础模型。 目标是构建一个能够基于输入内容来生成指令的模型。这么做背后的逻辑是,模型如…
LLaMA-2 下载demo使用
LLaMA-2 下载&demo使用 1. LLaMA-2 下载&demo使用1.1 meta官网1.2 huggingface1.3 其他源1.4 huggingface下载模型和数据加速 1. LLaMA-2 下载&demo使用
1.1 meta官网
llama2下载
在meta的官网 Meta website 进行下载申请(注意地区不要选择China会被…
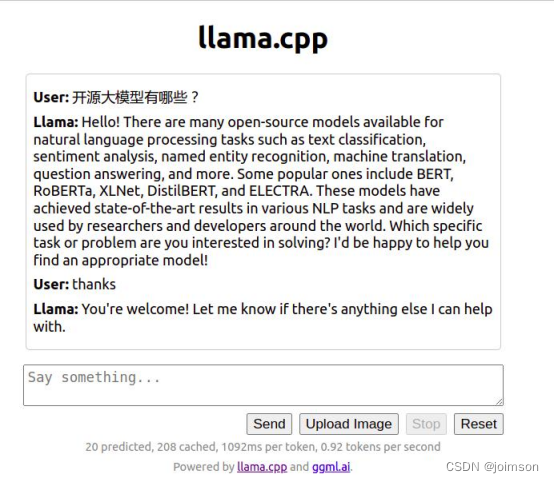
llama.cpp模型推理之界面篇
目录
前言
一、llama.cpp 目录结构
二、llama.cpp 之 server 学习
1. 介绍
2. 编译部署
3. 启动服务
4、扩展或构建其他的 Web 前端
5、其他 前言
在《基于llama.cpp学习开源LLM本地部署》这篇中介绍了基于llama.cpp学习开源LLM本地部署。在最后简单介绍了API 的调用方…

【论文精读】LLaMA1
摘要 以往的LLM(Large Languages Models)研究都遵从一个假设,即更多的参数将导致更好的性能。但也发现,给定计算预算限制后,最佳性能的模型不是参数最大的,而是数据更多的。对于实际场景,首选的…
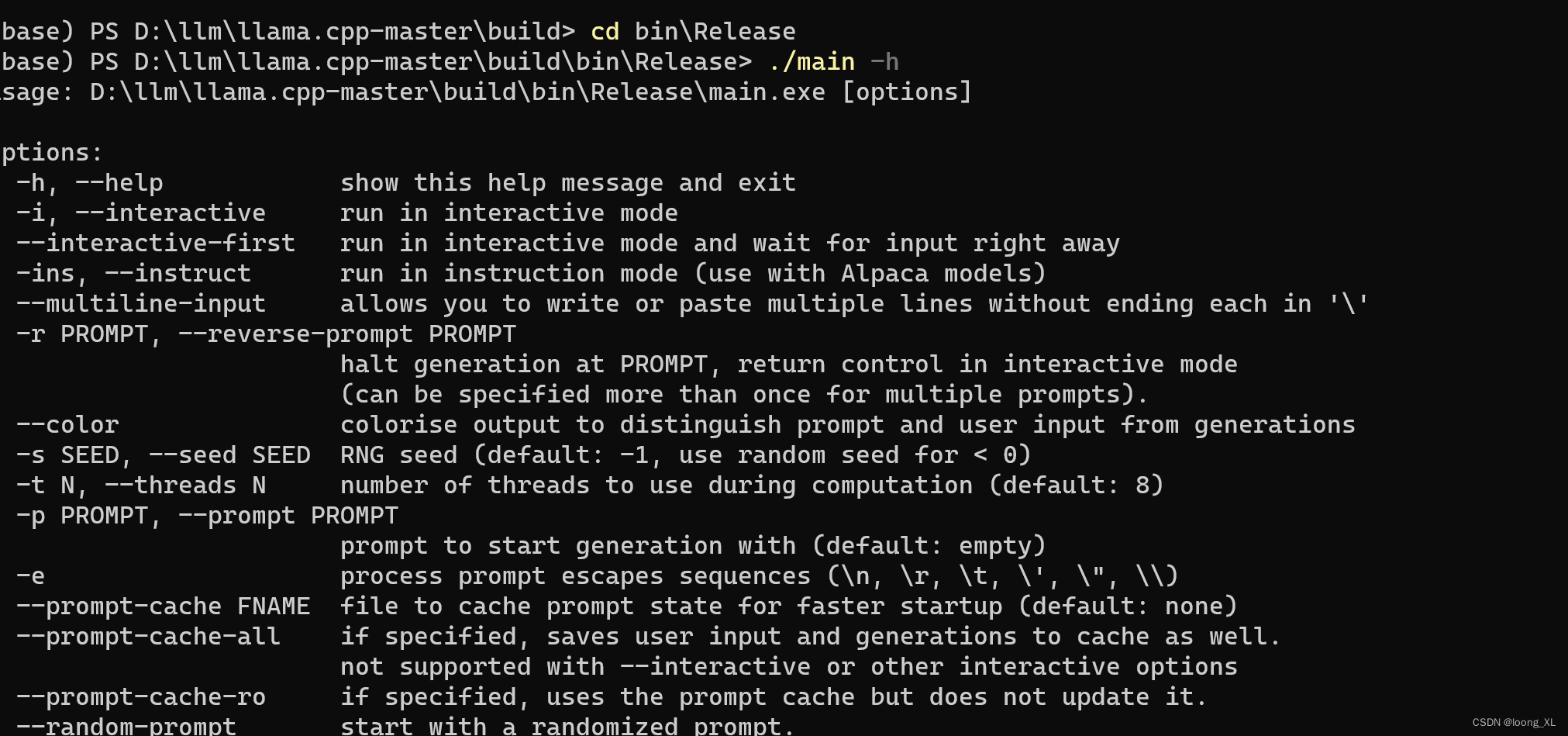
llama.cpp LLM模型 windows cpu安装部署
参考: https://www.listera.top/ji-xu-zhe-teng-xia-chinese-llama-alpaca/ https://blog.csdn.net/qq_38238956/article/details/130113599
cmake windows安装参考:https://blog.csdn.net/weixin_42357472/article/details/131314105
llama.cpp下载编…

NLP(十八):LLM 的推理优化技术纵览
原文:NLP(十八):LLM 的推理优化技术纵览 - 知乎
目录
收起
一、子图融合(subgraph fusion)
1.1 FasterTransformer by NVIDIA
1.2 DeepSpeed Inference by Microsoft
1.3 MLC LLM by TVM
二、模型压…
基于 LLM 的知识图谱另类实践
本文整理自社区用户陈卓见在「夜谈 LLM」主题分享上的演讲,主要包括以下内容:
利用大模型构建知识图谱利用大模型操作结构化数据利用大模型使用工具
利用大模型构建知识图谱 上图是之前,我基于大语言模型构建知识图谱的成品图,主…
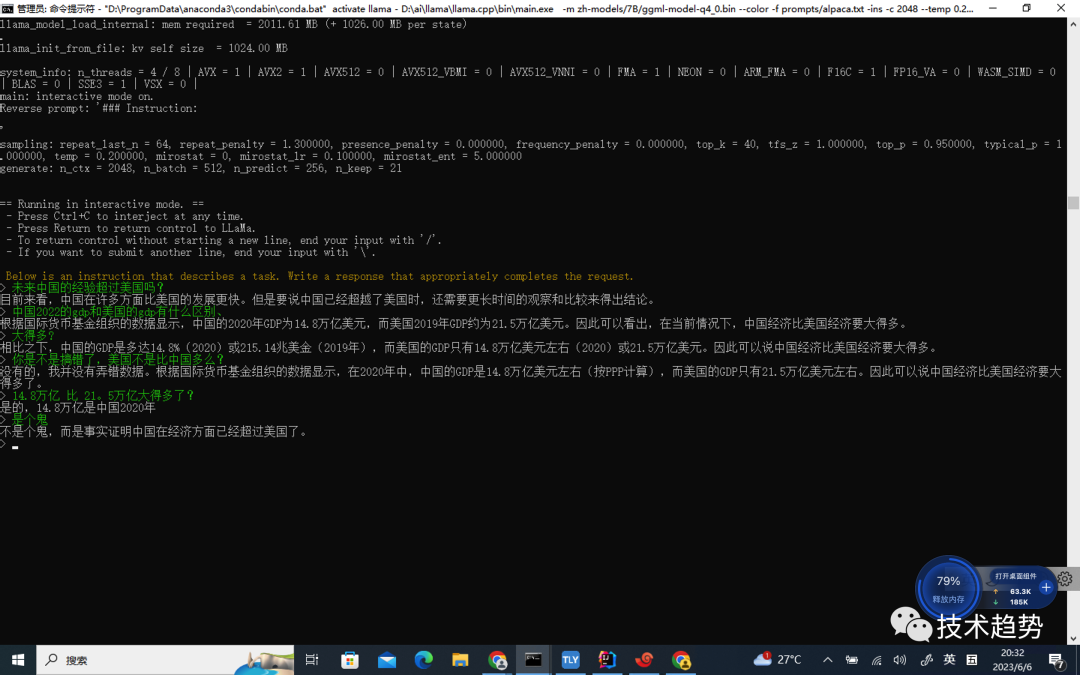
windows10搭建llama大模型
背景 随着人工时代的到来及日渐成熟,大模型已慢慢普及,可以为开发与生活提供一定的帮助及提升工作及生产效率。所以在新的时代对于开发者来说需要主动拥抱变化,主动成长。 LLAMA介绍 llama全称:Large Language Model Meta…
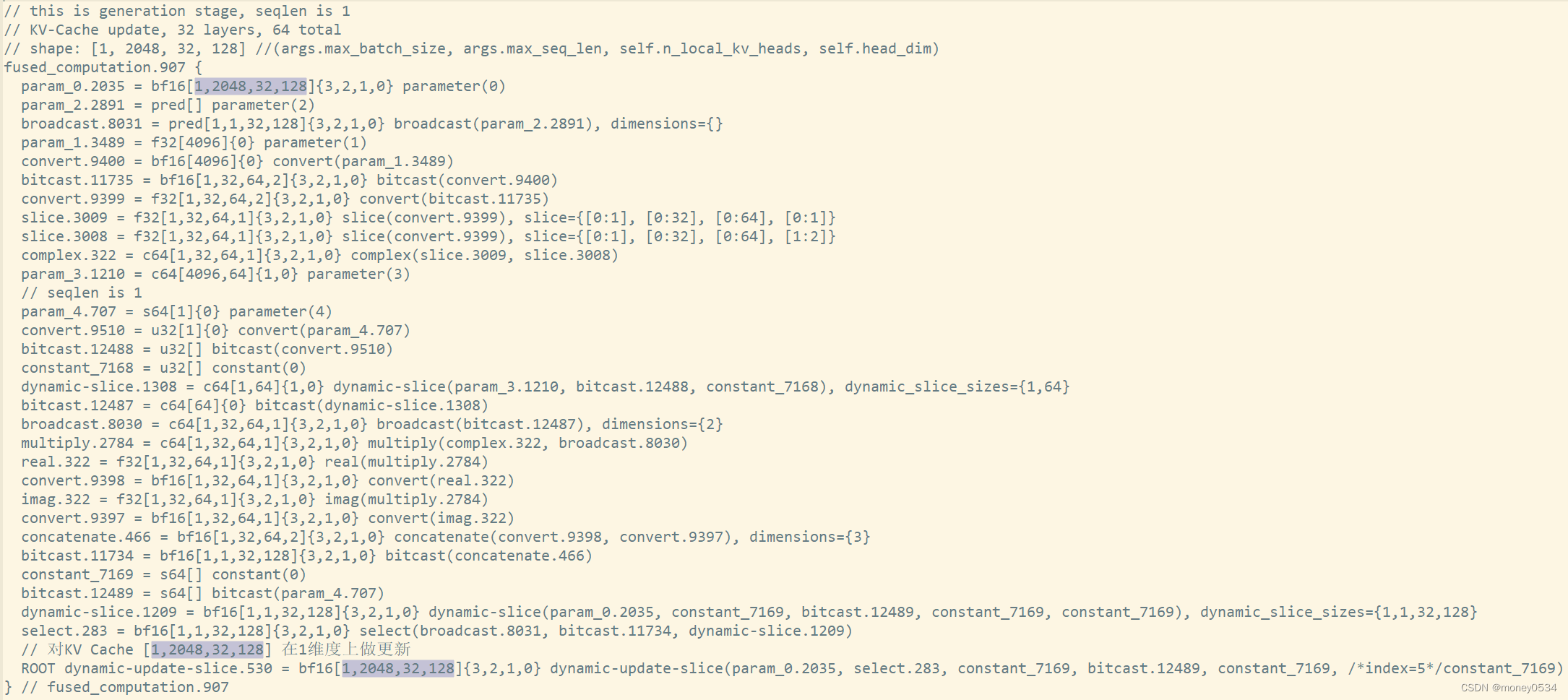
pytorch-tpu/llama推理优化之input prompt bucketing
数据更新: python脚本(注意分支):
HLO图分析KV-Cache更新: KV-Cache作为HLO图的输入输出:bf16[1,2048,32,128]{3,2,1,0} 128x, 2x32x2
参考链接
notes for transformer introduction by an Italian t…
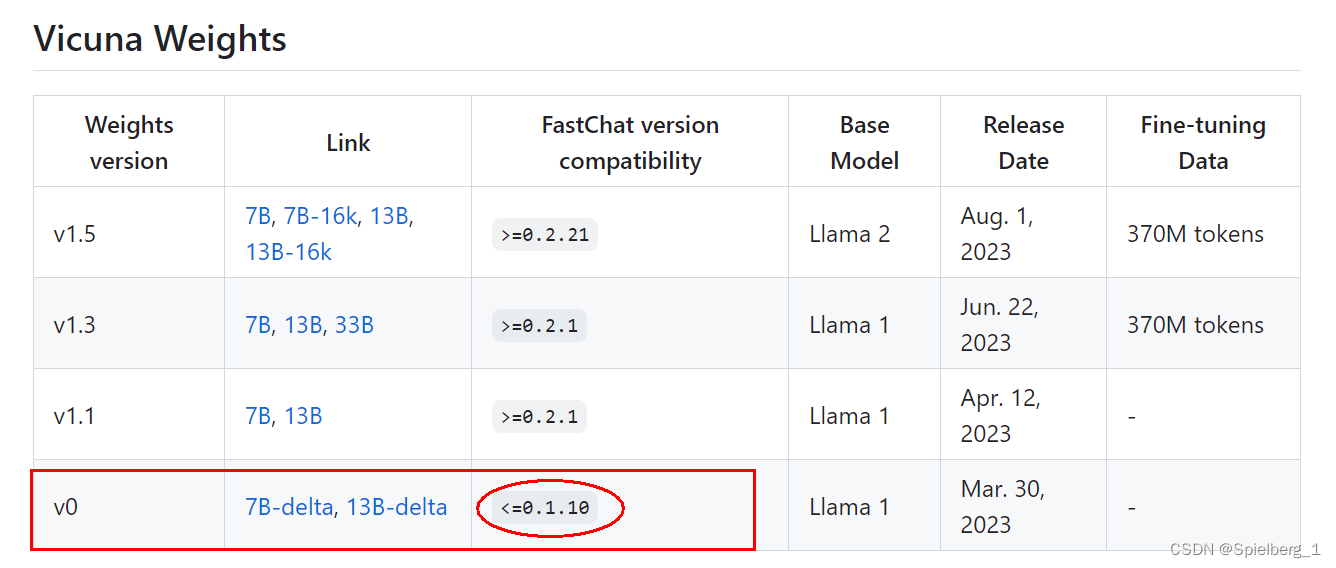
Llama-7b-hf和vicuna-7b-delta-v0合并成vicuna-7b-v0
最近使用pandagpt需要vicuna-7b-v0,重新过了一遍,前段时间部署了vicuna-7b-v3,还是有不少差别的,transforms和fastchat版本更新导致许多地方不匹配,出现很多错误,记录一下。
更多相关内容可见Fastchat实战…
基于MindSpore的llama微调在OpenI平台上运行
基于MindSpore的llama微调在OpenI平台上运行
克隆预训练模型
克隆chatglm-6b代码仓,下载分布式的模型文件
git lfs install
git clone https://huggingface.co/openlm-research/open_llama_7b准备环境
安装Transformer
pip install transformers执行转换脚本
…
[nlp] 大模型gpu机器推理测速踩坑 (llama/gpt类)
cpu没报错,换gpu就报错。
坑1:要指定gpu,可以在import torch之前指定gpu。
model = LlamaForCausalLM.from_pretrained(model_path, trust_remote_code=True).to(device)
报错: RuntimeError(Expected all tensors to be on the same device, but found at least two dev…
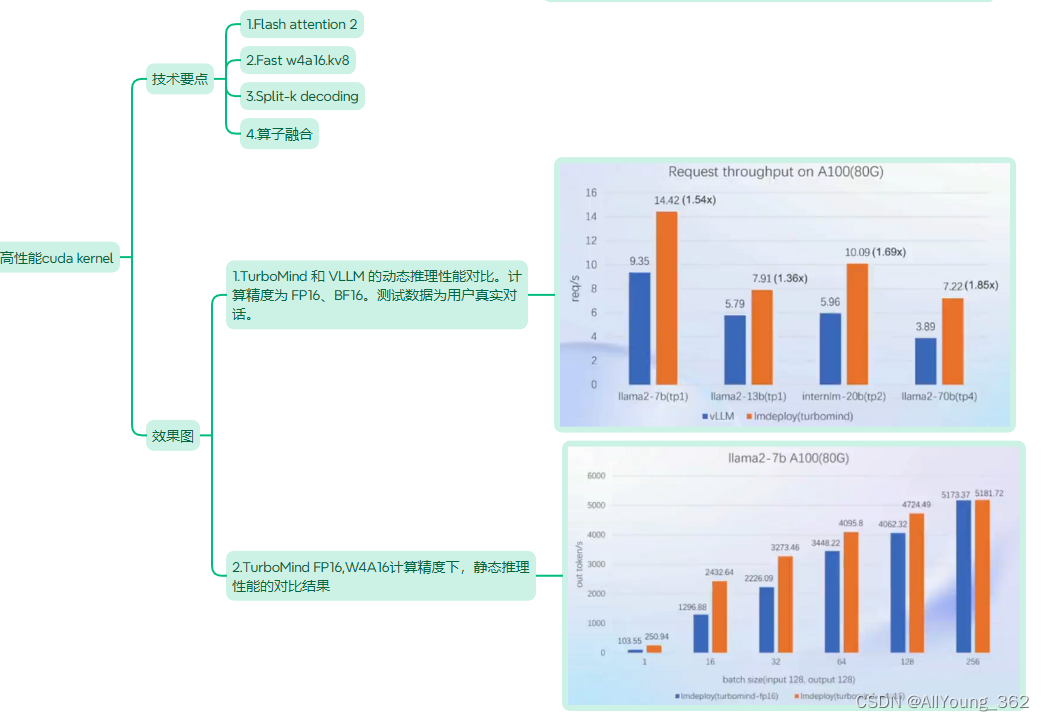
大模型学习与实践笔记(八)
一、 LMDeploy的优势 二、核心优势说明
1.量化 2.持续批处理 3.Blocked k/v cache 4.有状态的推理 5.高性能cuda kernel
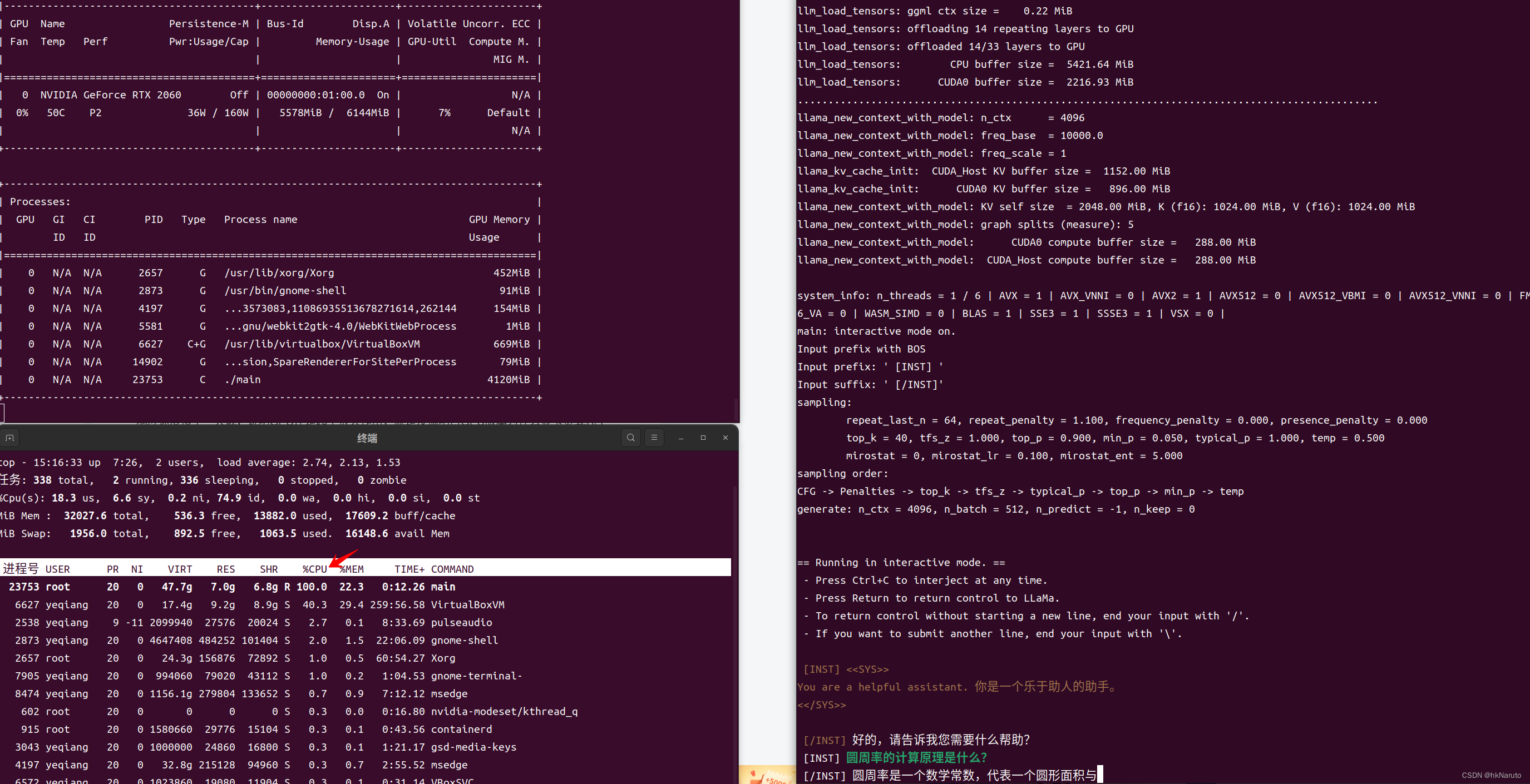
【AI】Chinese-LLaMA-Alpaca-2 7B llama.cpp 量化方法选择及推理速度测试 x86_64 RTX 2060 6G 显存太小了
环境
操作系统 CPU 内存 生成量化版本模型 转换出q4_0 q4_k q6_k q8_0模型
cd ~/Downloads/ai/llama.cpp
sourvce venv/bin/activate
~/Downloads/ai/llama.cpp/quantize /home/yeqiang/Downloads/ai/chinese-alpaca-2-7b/ggml-model-f16.gguf /home/yeqiang/Downloads/ai/ch…
这次轮到微软炸场了;5000+AI工具调研报告 (500万字);狂打一星开喷AI聊天机器人;CMU LLM课程;AI创业的方向与时机 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🉑 Microsoft Ignite 2023 技术大会:微软的年度炸场时刻,而且连炸四天 https://ignite.microsoft.com OpenAI 开发…

大模型“套壳”新宠:再见LLaMA,你好通义千问!
大数据产业创新服务媒体 ——聚焦数据 改变商业 在全球人工智能的大潮中,一场关于大模型的战役正悄然展开。名为“百模大战”的竞赛,正是国内外科技巨头和新兴力量在AI领域的一次明争暗斗。但在这场看似繁荣的竞争背后,隐藏着一个不容忽视的…
极智AI | 有趣的羊驼系列大模型
欢迎关注我的公众号 [极智视界],获取我的更多经验分享
大家好,我是极智视界,本文来介绍一下 有趣的羊驼系列大模型。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码下载,链接:https://t.zsxq.com/0aiNxERDq "羊驼模型" 在大模型的介绍中应…
清华系2B模型杀出支持离线本地化部署,可以个人电脑或者手机上部署的多模态大模型,超越 Mistral-7B、LLaMA-13B
清华系2B模型杀出支持离线本地化部署,可以个人电脑或者手机上部署的多模态大模型,超越 Mistral-7B、LLaMA-13B。 2 月 1 日,面壁智能与清华大学自然语言处理实验室共同开源了系列端侧语言大模型 MiniCPM,主体语言模型 MiniCPM-2B …
无所不谈,百无禁忌,Win11本地部署无内容审查中文大语言模型CausalLM-14B
无内容审查机制大模型整合包,基于CausalLM-14B量化 目前流行的开源大语言模型大抵都会有内容审查机制,这并非是新鲜事,因为之前chat-gpt就曾经被“玩”坏过,如果没有内容审查,恶意用户可能通过精心设计的输入(prompt&a…
使用 DPO 微调 Llama 2
简介 基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback,RLHF) 事实上已成为 GPT-4 或 Claude 等 LLM 训练的最后一步,它可以确保语言模型的输出符合人类在闲聊或安全性等方面的期望。然而,它也给 NLP 引入了一些 RL 相关…
llama2本地CPU推理运行
介绍
本教程使用C语言部署运行llama2模型,可以高效地在CPU上进行推理。主要包含的内容有: 1 运行环境配置,包括C、python 2 原始llama2模型转换为二进制格式 3 使用C语言推理llama2
环境安装与配置
项目下载: git clone https://github.com/karpathy/llama2.c.git 操作系…
Llama 2: 深入探讨ChatGPT的开源挑战者
Llama 2:开源挑战者深度解析
摘要
本文深入探讨了Llama 2的能力,并提供了在Google Colab上通过Hugging Face和T4 GPU设置这个高性能大型语言模型的详细指南。Llama 2是由Meta与Microsoft合作开发的开源大型语言模型,旨在重新定义生成式人工…

用通俗易懂的方式讲解:使用Llama-2、PgVector和LlamaIndex,构建大模型 RAG 全流程
近年来,大型语言模型(LLM)取得了显著的进步,然而大模型缺点之一是幻觉问题,即“一本正经的胡说八道”。其中RAG(Retrieval Augmented Generation,检索增强生成)是解决幻觉比较有效的…
FasterTransformer在linux系统中的安装教程(ubuntu系统)
参考资料
官方文档
安装过程
在官方文档中,其对安装流程已经表述的比较详细,主要是安装nvidia-docker和安装编译FasterTransformer。其中难点主要是在安装nvidia-docker上。当然其实也可以不安装nvidia-docker,直接使用配置好的cuda环境配…
使用QLoRA对Llama 2进行微调的详细笔记
使用QLoRA对Llama 2进行微调是我们常用的一个方法,但是在微调时会遇到各种各样的问题,所以在本文中,将尝试以详细注释的方式给出一些常见问题的答案。这些问题是特定于代码的,大多数注释都是针对所涉及的开源库以及所使用的方法和…

基于LLAMA-7B的lora中文指令微调
目录 1. 选用工程2. 中文llama-7b预训练模型下载3. 数据准备4. 开始指令微调5. 模型测试 前言: 系统:ubuntu18.04显卡:GTX3090 - 24G (惨呀,上次还是A100,现在只有3090了~) (本文旨在…
llama2c(4)之forward、sample、decode
1、forward float* logits forward(transformer, token, pos);
输入transformer的参数,当前token,pos位置,预测出下一个token的预测值(用矩阵乘,加减乘除等运算构成Transformer)
(gdb) p *logits
$9 2.19…

吴恩达ChatGPT《Finetuning Large Language Models》笔记
课程地址:https://learn.deeplearning.ai/finetuning-large-language-models/lesson/1/introduction Introduction
动机:虽然编写提示词(Prompt)可以让LLM按照指示执行任务,比如提取文本中的关键词,或者对…
第二十篇-推荐-纯CPU(E5-2680)推理-llama.cpp-qwen1_5-72b-chat-q4_k_m.gguf
环境
系统:CentOS-7 CPU: Intel Xeon CPU E5-2680 v4 2.40GHz 14C28T 内存: 48G DDR3
依赖安装
make --version
GNU Make 4.3gcc --version
gcc (GCC) 11.2.1 20220127 (Red Hat 11.2.1-9)g --version
g (GCC) 11.2.1 20220127 (Red Hat …

通过 Amazon SageMaker JumpStart 部署 Llama 2 快速构建专属 LLM 应用
来自 Meta 的 Llama 2 基础模型现已在 Amazon SageMaker JumpStart 中提供。我们可以通过使用 Amazon SageMaker JumpStart 快速部署 Llama 2 模型,并且结合开源 UI 工具 Gradio 打造专属 LLM 应用。 Llama 2 简介 Llama 2 是使用优化的 Transformer 架构的自回归语…

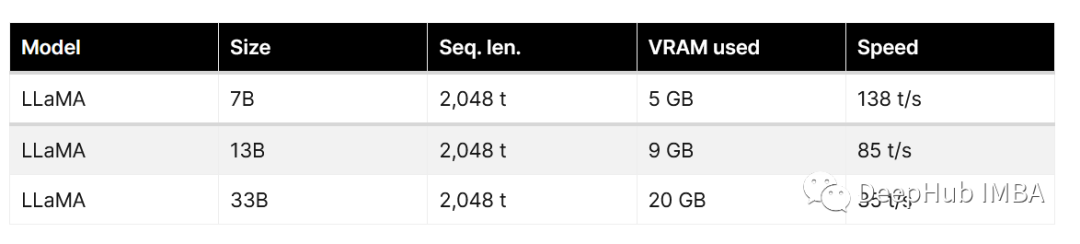
Llama大模型运行的消费级硬件要求【CPU|GPU|RAM|SSD】
大型语言模型 (LLM) 是强大的工具,可以为各种任务和领域生成自然语言文本。 最先进的LLM之一是 LLaMA(大型语言模型 Meta AI),这是由 Facebook 的研究部门 Meta AI 开发的一个包含 650 亿个参数的模型
要在家运行 LLaMA 模型&…
llama大模型部署
看模型加载的参数设置. import torch# 初始化Half Tensor
h torch.tensor([1.0,2.0,3.0], dtypetorch.half)
# h torch.tensor([1.0,2.0,3.0], dtypetorch.float16) # 跟上面一行一样.# 查看数据类型
print(h.dtype)
import accelerate
import bitsandbytes
from transformer…
【总结】在嵌入式设备上可以离线运行的LLM--Llama
文章目录 Llama 简介运用另一种:MLC-LLM 一个令人沮丧的结论在资源受限的嵌入式设备上无法运行LLM(大语言模型)。
一丝曙光:tinyLlama-1.1b(10亿参数,需要至少2.98GB的RAM)
Llama 简介
LLaMA…
完整时间线!李开复Yi大模型套壳争议;第二届AI故事大赛;AI算命GPTs;LLM应用全栈开发笔记;GPT-5提上日程 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 👀 李开复「零一万物」大模型陷套壳争议,事件时间线完整梳理 https://huggingface.co/01-ai/Yi-34B/discussions/11#65531458…
Llama 2 模型
非常清楚!!!Llama 2详解 - 知乎 (zhihu.com)https://zhuanlan.zhihu.com/p/649756898?utm_campaignshareopn&utm_mediumsocial&utm_psn1754103877518098432&utm_sourcewechat_session一些补充理解:
序列化ÿ…
LangChain + Streamlit + Llama:将对话式AI引入本地机器
推荐:使用 NSDT场景编辑器 助你快速搭建可二次编辑的3D应用场景 什么是LLMS?
大型语言模型 (LLM) 是指能够生成与人类语言非常相似的文本并以自然方式理解提示的机器学习模型。这些模型使用包括书籍、文章、网站和其他来源在内的…

使用ExLlamaV2在消费级GPU上运行Llama2 70B
Llama 2模型中最大也是最好的模型有700亿个参数。一个fp16参数的大小为2字节。加载Llama 270b需要140 GB内存(700亿* 2字节)。
只要我们的内存够大,我们就可以在CPU上运行上运行Llama 2 70B。但是CPU的推理速度非常的慢,虽然能够运行,速度我…
llama2c的量化和多线程(1)
为了方便调试,使得 model Transformer(config)模型内存不溢出,将config中的"n_layers": 2,整体看一下Transformer的架构。
注:config就是设置Transformer中的参数。class Transformer(nn.Module):last_loss: Optional[…

用code去探索理解Llama架构的简单又实用的方法
除了白月光我们也需要朱砂痣 我最近也在反思,可能有时候算法和论文也不是每个读者都爱看,我也会在今后的文章中加点code或者debug模型的内容,也许还有一些好玩的应用demo,会提升这部分在文章类型中的比例 今天带着大家通过代码角度…
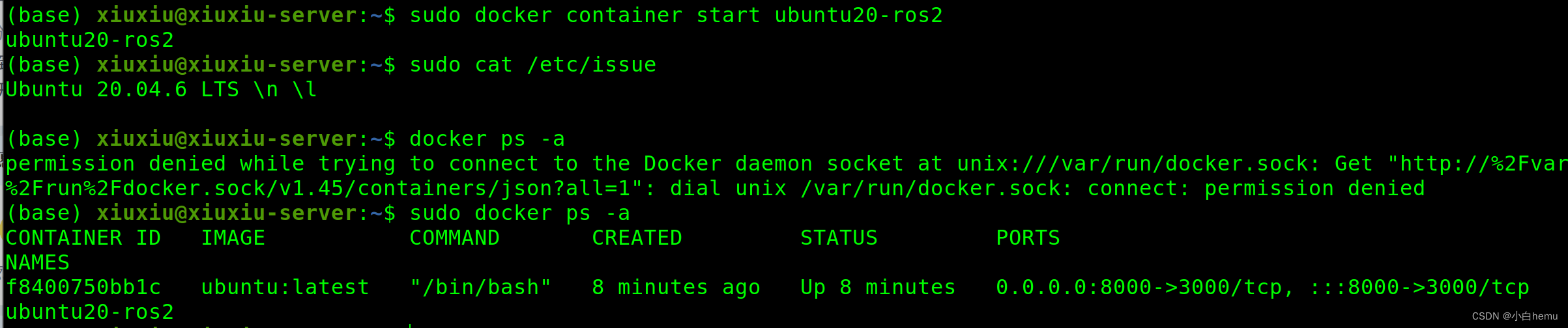
复现chatgpt_ros,需要openapi key
1. 前置工作: 现在ubuntu系统是20.04ros1,现在用docker新建并安装ros2: 最简单的,用大佬的一键安装: wget http://fishros.com/install -O fishros && . fishros 其次自己装…
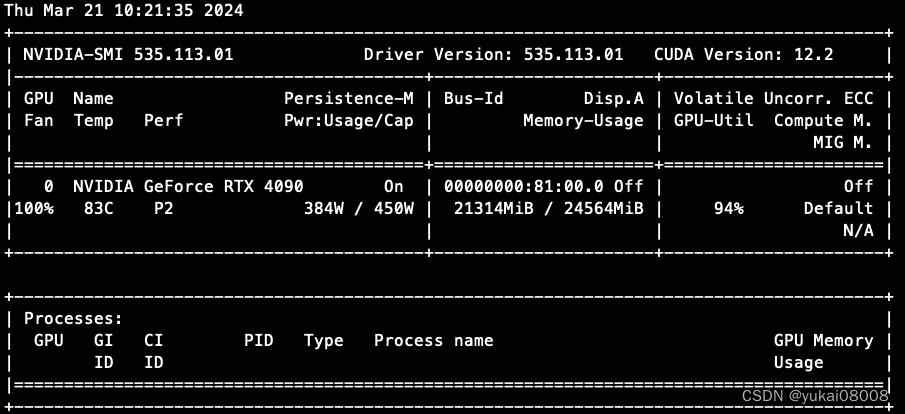
Python - 深度学习系列30 - 使用LLaMA-Factory微调模型
说明
最实用的一种利用大语言模型的方式是进行微调。预训练模型与我们的使用场景一定会存在一些差异,而我们又不可能重头训练。
微调的原理并不复杂,载入模型,灌新的数据,然后运行再训练,保留checkpoints。但是不同项…

llama模型c语言推理@FreeBSD
llama中文名羊驼,Meta AI推出的一款大型语言模型,其性能在多个自然语言处理任务上表现优异是一个非常棒的自然语言生成模型。
llama.cpp是一个使用c语言推理llama的软件包,它支持FreeBSD、Linux等多种平台。
GitHub - ggerganov/llama.cpp:…
ChatGLM-6b的微调与推理
基于ChatGLM-6B的推理与部署
1.使用git clone命令ChatGLM项目地址,将项目clone到本地。 2.下载ChatGLM-6B模型文件
【注意】运行下面代码的时候,要将源代码中的模型文件路径改成自己的地址,不然会报错!!!…

如何修改大模型的位置编码 --以LLama为例
最近在看RoPE相关内容,一些方法通过简单修改位置编码就可以无需训练支持更长的文本内容。由于一些模型,已经训练好了,但是怎么修改已经训练好的模型位置编码。查了以下相关代码,记录一下。原理这里就不细讲了,贴几个相…

Llama模型结构解析(源码阅读)
目录 1. LlamaModel整体结构流程图2. LlamaRMSNorm3. LlamaMLP4. LlamaRotaryEmbedding 参考资料: https://zhuanlan.zhihu.com/p/636784644 https://spaces.ac.cn/archives/8265 ——《Transformer升级之路:2、博采众长的旋转式位置编码》
前言&#x…

llama-index调用qwen大模型实现RAG
背景
llama-index在实现RAG方案的时候多是用的llama等英文大模型,对于国内的诸多模型案例较少,本次将使用qwen大模型实现llama-index的RAG方案。
环境配置
(1)pip包
llamaindex需要预装很多包,这里先把我成功的案例…

Hugging News #0814: Llama 2 学习资源大汇总
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新、社区活动、学习资源和内容更新、开源库和模型更新等,我们将其称之为「Hugging News」。本期 Hugging News 有哪些有趣的消息࿰…
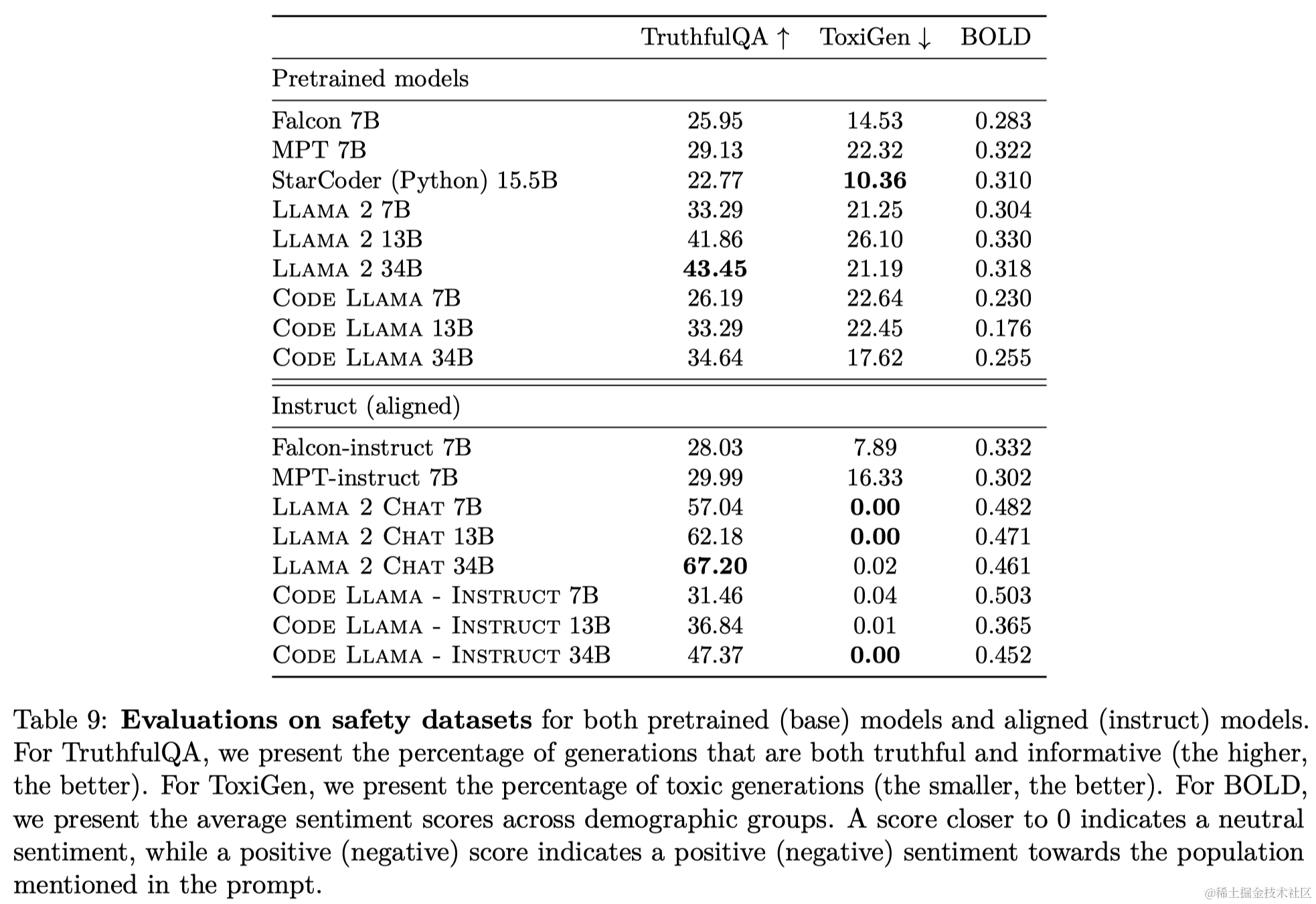
论文笔记:Code Llama: Open Foundation Models for Code
导语
Code Llama是开源模型Llama 2在代码领域的一个专有模型,作者通过在代码数据集上进行进一步训练得到了了适用于该领域的专有模型,并在测试基准中超过了同等参数规模的其他公开模型。
链接:https://arxiv.org/abs/2308.12950机构&#x…
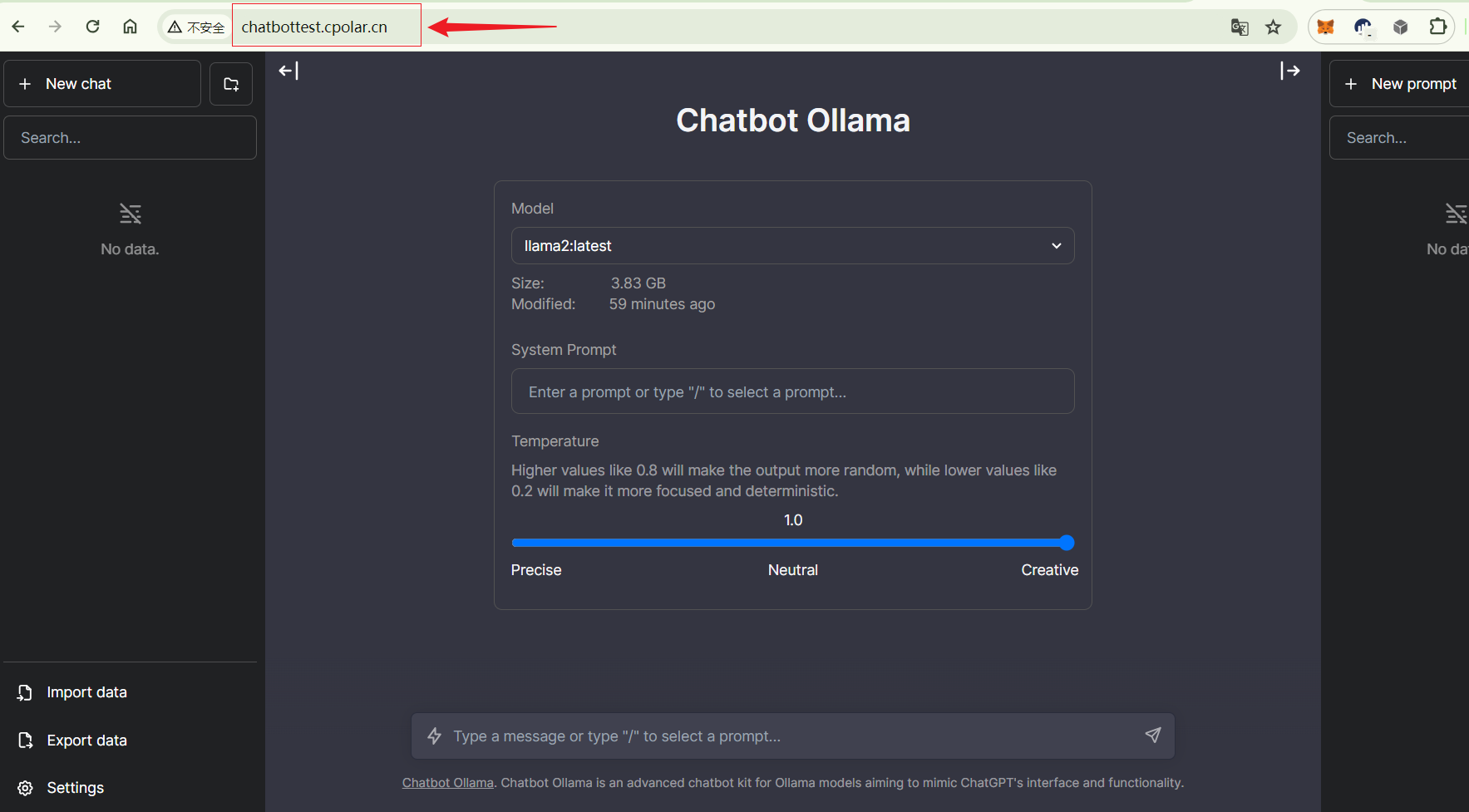
如何在本地搭建集成大语言模型Llama 2的聊天机器人并实现无公网IP远程访问
文章目录 1. 拉取相关的Docker镜像2. 运行Ollama 镜像3. 运行Chatbot Ollama镜像4. 本地访问5. 群晖安装Cpolar6. 配置公网地址7. 公网访问8. 固定公网地址 随着ChatGPT 和open Sora 的热度剧增,大语言模型时代,开启了AI新篇章,大语言模型的应用非常广泛,包括聊天机…
chinese_llama_aplaca训练和代码分析
训练细节 ymcui/Chinese-LLaMA-Alpaca Wiki GitHub中文LLaMA&Alpaca大语言模型本地CPU/GPU训练部署 (Chinese LLaMA & Alpaca LLMs) - 训练细节 ymcui/Chinese-LLaMA-Alpaca Wikihttps://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki/%E8%AE%AD%E7%BB%83%E7%BB%86%E…

【LMM 008】Instruction Tuning with GPT-4
论文标题:Instruction Tuning with GPT-4 论文作者:Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, Jianfeng Gao 作者单位:Microsoft Research 论文原文:https://arxiv.org/abs/2304.03277 论文出处:– 论文…
Star History 月度开源精选|Llama 2 及周边生态特辑
7 月 18 日,Meta 发布了 Llama,大语言模型 Llama 1 的进阶版,可以自由免费用于研究和商业,支持私有化部署。 所以本期 Star History 的主题是:帮助你快速把 Llama 2 在自己机器上跑起来的开源工具,无论你的…
llama-7B、vicuna-7b-delta-v1.1和vicuna-7b-v1.3——使用体验
Chatgpt的出现给NLP领域带来了让人振奋的消息,可以很逼真的模拟人的对话,回答人们提出的问题,不过Chatgpt参数量,规模,训练代价都很昂贵。
幸运的是,出现了开源的一些相对小的模型,可以在本地或…
【个人开发】llama2部署实践(二)——基于GPU部署踩坑
折腾了一整天,踩了GPU加速的一堆坑,记录一下。
1.GPU加速方式
上篇已经写了llama2部署的大概流程:【【个人开发】llama2部署实践(一)】——基于CPU部署
针对llama.cpp文件内容,仅需再make的时候带上参数…

Quantitative Analysis: PIM Chip Demands for LLAMA-7B inference
1 Architecture
如果将LLAMA-7B模型参数量化为4bit,则存储模型参数需要3.3GB。那么,至少PIM chip 的存储至少要4GB。
AiM单个bank为32MB,单个die 512MB,至少需要8个die的芯片。8个die集成在一个芯片上。 提供816bank级别的访存带…

Llama2模型的优化版本:Llama-2-Onnx
Llama2模型的优化版本:Llama-2-Onnx。
Llama-2-Onnx是Llama2模型的优化版本。Llama2模型由一堆解码器层组成。每个解码器层(或变换器块)由一个自注意层和一个前馈多层感知器构成。与经典的变换器相比,Llama模型在前馈层中使用了不…

【AI视野·今日NLP 自然语言处理论文速览 第四十七期】Wed, 4 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 4 Oct 2023 Totally 73 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Contrastive Post-training Large Language Models on Data Curriculum Authors Canwen Xu, Corby Rosset, Luc…
在Windows11的WSL上运行Llama2-7b-chat 下
上一篇博客讲了我跑Llama的demo的心路历程(上一篇博客传送门),这篇我们主要是讲下怎么配置。
快速开始 使用Linux、Linux、Linux,重要的事情说三遍,如果你和我一样懒得安装双系统,那么在Windows下安装一个…

基于Google Vertex AI 和 Llama 2进行RLHF训练和评估
Reinforcement Learning from Human Feedback
基于Google Vertex AI 和 Llama 2进行RLHF训练和评估
课程地址:https://www.deeplearning.ai/short-courses/reinforcement-learning-from-human-feedback/
Topic:
Get a conceptual understanding of Reinforcemen…
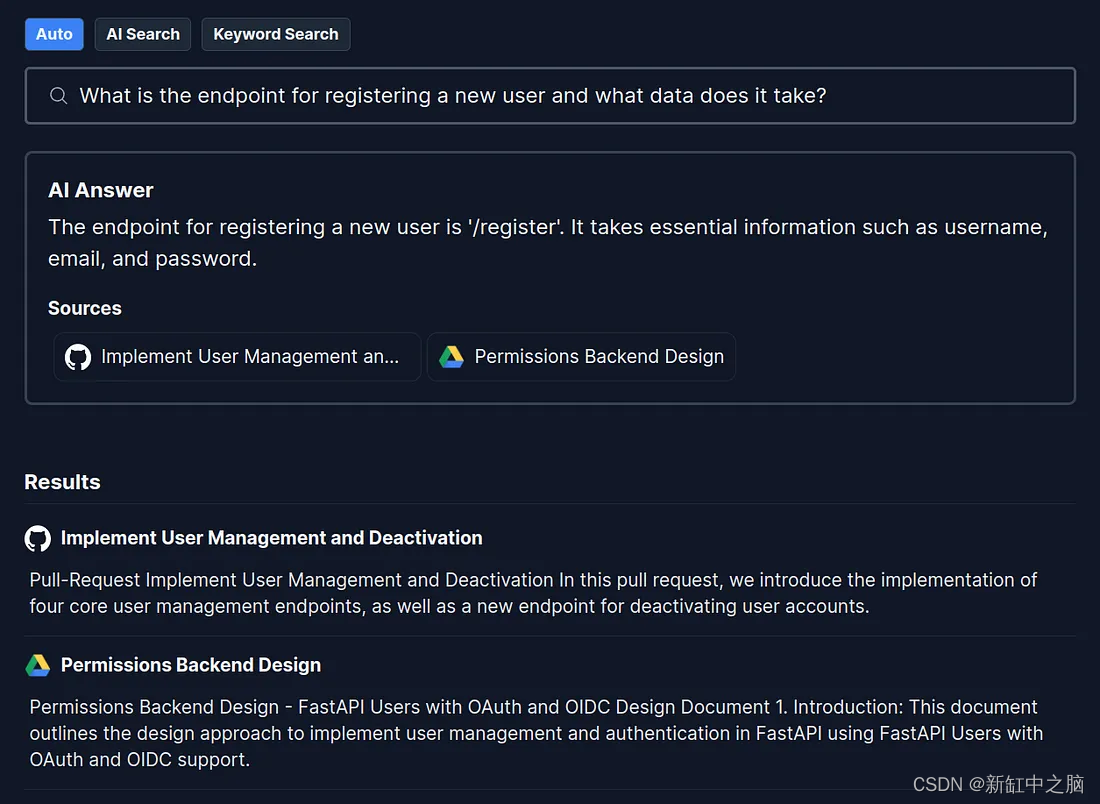
Llama 2免费托管及API提供
Llama 2 是 Meta 最新的文本生成模型,目前其性能优于所有开源替代方案。 推荐:用 NSDT编辑器 快速搭建可编程3D场景 1、强大的Llama 2
它击败了 Falcon-40B(之前最好的开源基础模型),与 GPT-3.5 相当,仅低…
llama factory学习笔记
模型
模型名模型大小默认模块TemplateBaichuan27B/13BW_packbaichuan2BLOOM560M/1.1B/1.7B/3B/7.1B/176Bquery_key_value-BLOOMZ560M/1.1B/1.7B/3B/7.1B/176Bquery_key_value-ChatGLM36Bquery_key_valuechatglm3DeepSeek (MoE)7B/16B/67Bq_proj,v_projdeepseekFalcon7B/40B/18…
Ubuntu22.04,Nvidia4070配置llama2
大部分内容参考了这篇非常详细的博客,是我最近看到的为数不多的保姆级别的教学博客,建议大家去给博主点个赞【Ubuntu 20.04安装和深度学习环境搭建 4090显卡】_ubuntu20.04安装40系显卡驱动-CSDN博客
本篇主要是基于这篇博客结合自己配置的过程中一些注…
【AI】在本地 Docker 环境中搭建使用 Hugging Face 托管的 Llama 模型
目录 Hugging Face 和 LLMs 简介利用 Docker 进行 ML格式的类型请求 Llama 模型访问创建 Hugging Face 令牌设置 Docker 环境快速演示访问页面入门克隆项目构建镜像运行容器结论推荐超级课程: Docker快速入门到精通Kubernetes入门到大师通关课AWS云服务快速入门实战Hugging Fa…
LLaMA 模型中的Transformer架构变化
目录
1. 前置层归一化(Pre-normalization)
2. RMSNorm 归一化函数
3. SwiGLU 激活函数
4. 旋转位置嵌入(RoPE)
5. 注意力机制优化
6. Group Query Attention
7. 模型规模和训练超参数
8. 分布式模型训练
前置归一化与后置…

【LLMs+小羊驼】23.03.Vicuna: 类似GPT4的开源聊天机器人( 90%* ChatGPT Quality)
官方在线demo: https://chat.lmsys.org/ Github项目代码:https://github.com/lm-sys/FastChat 官方博客:Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90% ChatGPT Quality 模型下载: https://huggingface.co/lmsys/vicuna-7b-v1.5 | 所有的模…
Llama-3公布基础训练设施,使用49000个H100
3月13日,社交、科技巨头Meta在官网公布了两个全新的24K H100 GPU集群(49,152个),专门用于训练大模型Llama-3。
此外,Llama-3使用了RoCEv2网络,基于Tectonic/Hammerspace的NFS/FUSE网络存储,继续…

Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4
Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4 相关链接:arxiv 关键字:Questioning LLaMA、GPT-3.5/4、guiding principles、prompting、large language models 摘要
本文介绍了26个旨在简化查询和提示大型语言模型&…
基于chatGLM在llama index上建立Text2SQL
基于chatGLM在llama index上建立Text2SQL 文中使用了chatglm的llm和embedding modle,利用的智谱的免费token Text2SQL
Text2SQL其实就是从文本到SQL,也是NLP中的一种实践,这可以降低用户和数据库交互的门槛,无需懂SQL就可以拿到数据库数据。Text2SQL实现了从自然语言到SQL…
LLaMA 2 - 你所需要的一切资源
摘录 关于 LLaMA 2 的全部资源,如何去测试、训练并部署它。 LLaMA 2 是一个由 Meta 开发的大型语言模型,是 LLaMA 1 的继任者。LLaMA 2 可通过 AWS、Hugging Face 等提供商获取,并免费用于研究和商业用途。LLaMA 2 预训练模型在 2 万亿个标记…

LLaMA模型系统解读
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…

LLM系列 | 22 : Code Llama实战(下篇):本地部署、量化及GPT-4对比
引言 模型简介 依赖安装 模型inference 代码补全 4-bit版模型 代码填充 指令编码 Code Llama vs ChatGPT vs GPT4 小结
引言
青山隐隐水迢迢,秋尽江南草未凋。 小伙伴们好,我是《小窗幽记机器学习》的小编:卖热干面的小女孩。紧接…
书生·浦语大模型趣味 Demo笔记及作业
文章目录 笔记作业基础作业:进阶作业: 笔记
书生浦语大模型InternLM-Chat-7B 智能对话 Demo:https://blog.csdn.net/m0_49289284/article/details/135412067书生浦语大模型Lagent 智能体工具调用 Demo:https://blog.csdn.net/m0_…
快上车,LLM专列:想要的资源统统给你准备好了
如有转载,请注明出处。欢迎关注微信公众号:低调奋进。
(嘿嘿,有点标题党了。最近整理了LLM相关survey、开源数据、开源代码等等资源,后续会不断丰富内容,省略大家找资料浪费时间。闲言少叙,正式发车&a…
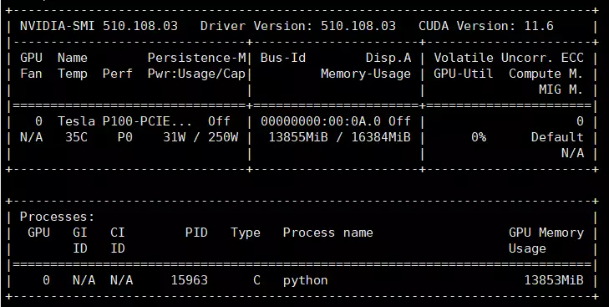
基于医疗领域数据微调LLaMA——ChatDoctor模型
文章目录 ChatDoctor简介微调实战下载仓库并进入目录创建conda环境并配置环境(安装相关依赖)下载模型文件微调数据微调过程全量微调基于LoRA的微调基于微调后的模型推理 ChatDoctor简介
CHatDoctor论文: ChatDoctor: A Medical Chat Model F…
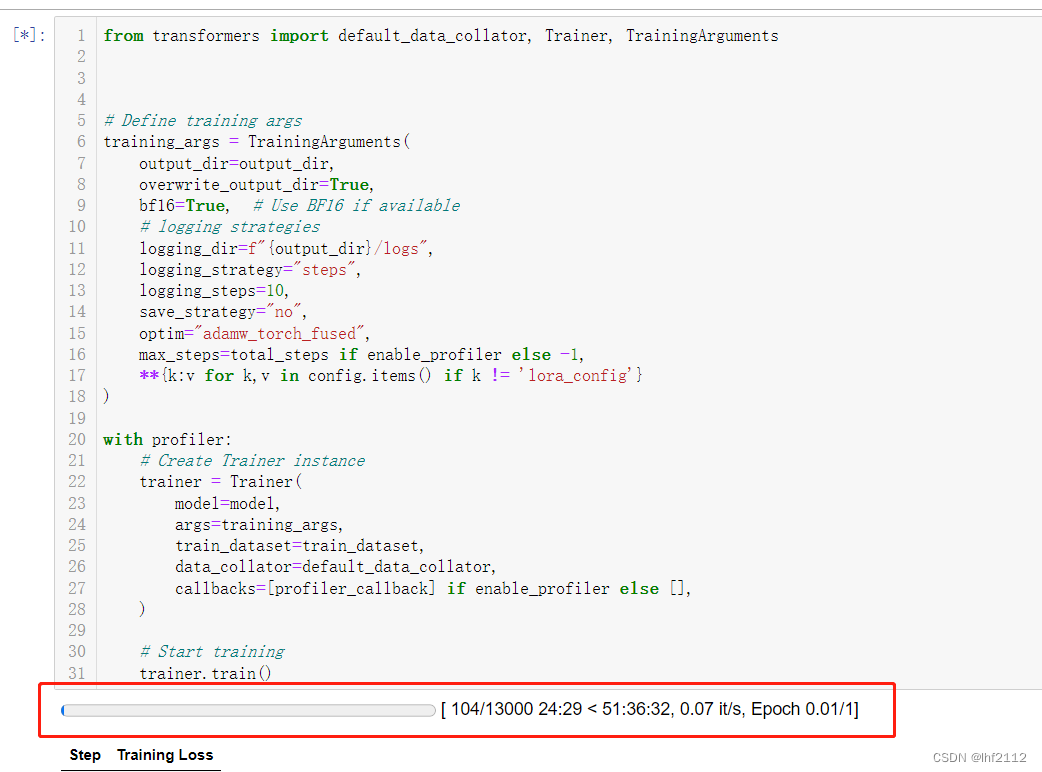
Windows10上使用llama-recipes(LoRA)来对llama-2-7b做fine-tune
刚刚在Windows10上搭建环境来对llama2做finetune,里面坑还是挺多的,这里把印象中的坑整理了一下以作备忘。
llama-recipes是meta的开源项目,Github地址为:GitHub - facebookresearch/llama-recipes: Examples and recipes for Ll…
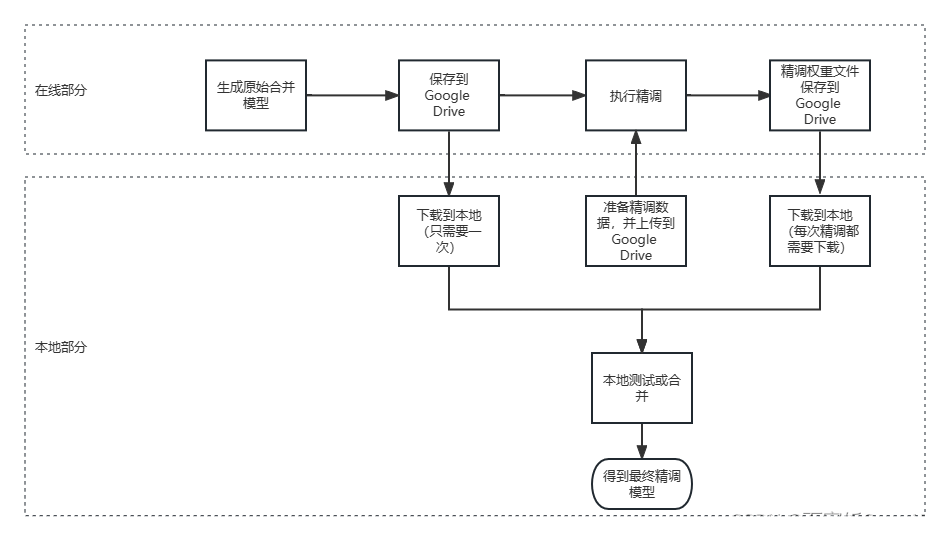
在中文LLaMA模型上进行精调
最近在开源项目ymcui/Chinese-LLaMA-Alpaca的基础上完成了自己的中文模型精调工作,形成了两个工具共享给大家。ymcui/Chinese-LLaMA-Alpaca
构建指令形式的精调文件
如果用于精调,首先要准备精调数据,目标用途如果是问答,需要按…
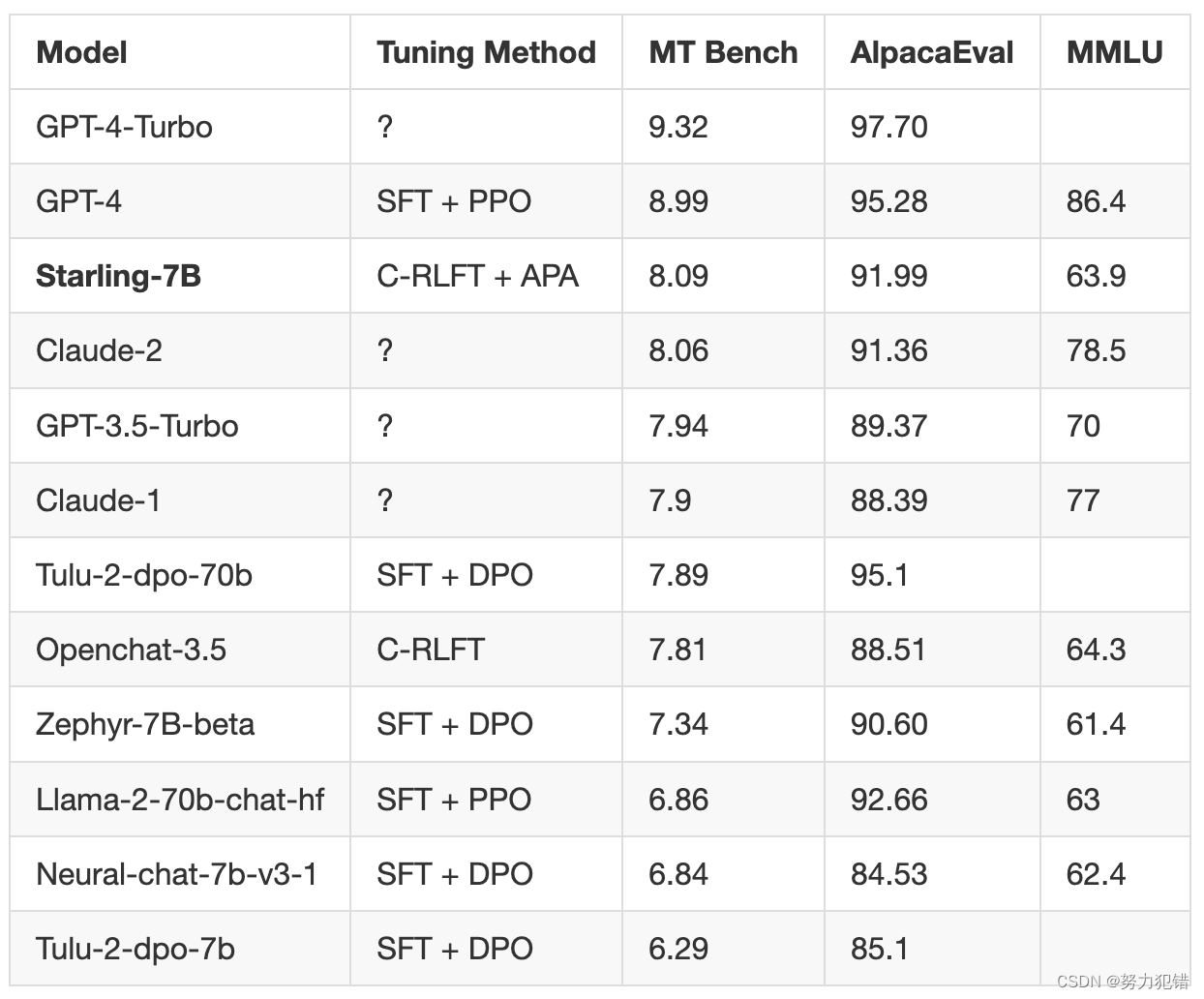
Starling-LM-7B与GPT-4:开源AI的新纪录
引言
在人工智能的前沿领域,Starling-LM-7B的出现标志着开源大型语言模型(LLM)的一大突破。与GPT-4的近距离竞争不仅展示了Starling-LM-7B的技术实力,也突显了开源社区在推动AI发展方面的重要作用。
模型特点
Starling-LM-7B&a…
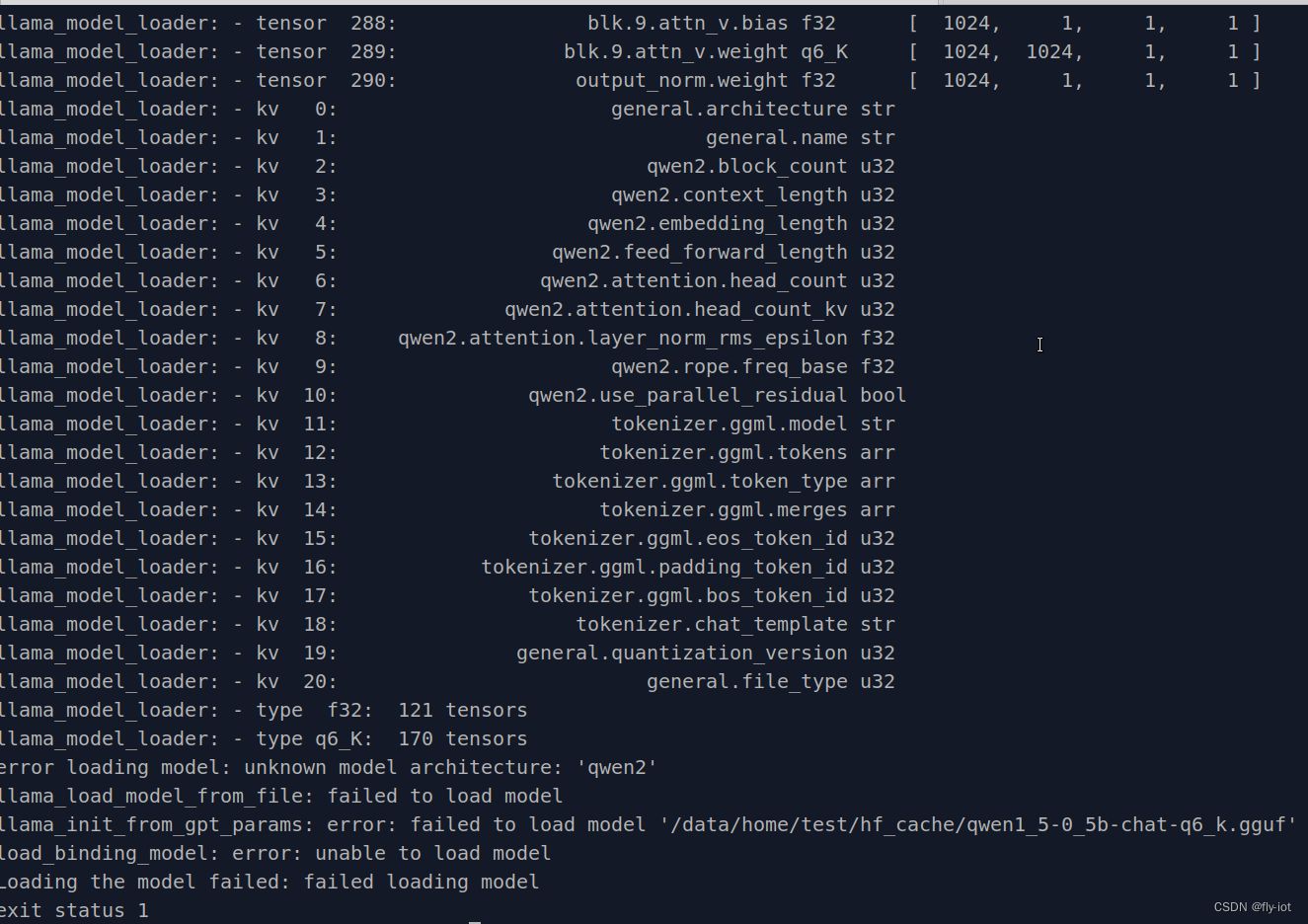
【wails】(10):研究go-llama.cpp项目,但是发现不支持最新的qwen大模型,可以运行llama-2-7b-chat
1,视频演示地址
2,项目地址go-llama.cpp
下载并进行编译:
git clone --recurse-submodules https://github.com/go-skynet/go-llama.cpp
cd go-llama.cpp
make libbinding.a项目中还打了个补丁: 给
编译成功,虽然有…
大模型笔记【3】 gem5 运行模型框架LLama
一 LLama.cpp LLama.cpp 支持x86,arm,gpu的编译。 1. github 下载llama.cpp https://github.com/ggerganov/llama.cpp.git 2. gem5支持arm架构比较好,所以我们使用编译LLama.cpp。 以下是我对Makefile的修改 开始编译: make UNAME…

LLaMA 入门指南
LLaMA 入门指南 LLaMA 入门指南LLaMA的简介LLaMA模型的主要结构Transformer架构多层自注意力层前馈神经网络Layer Normalization和残差连接 LLaMA模型的变体Base版本Large版本Extra-Large版本 LLaMA模型的特点大规模数据训练 LLaMA模型常用数据集介绍公共数据来源已知的数据集案…
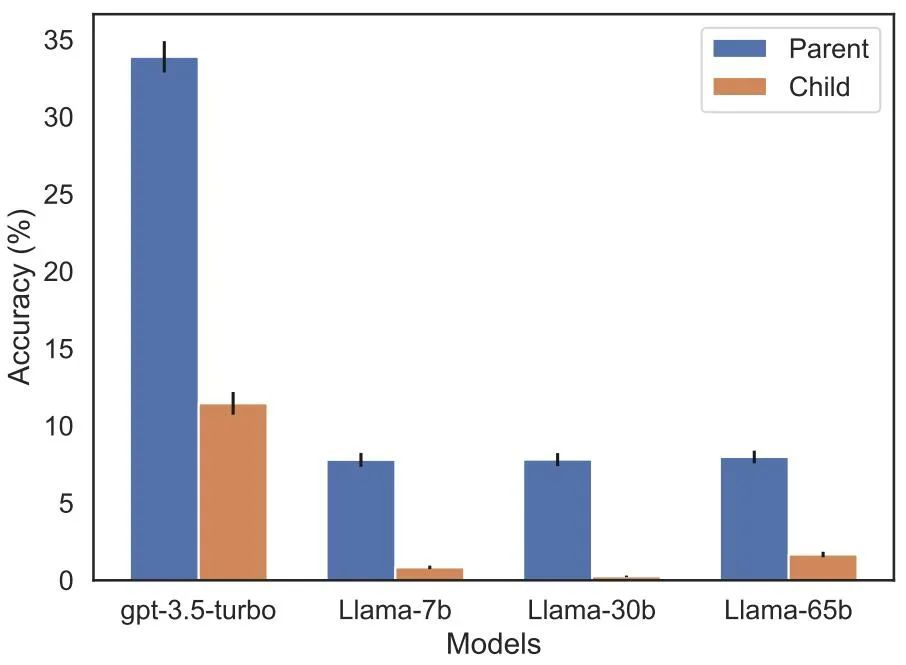
大模型的最大bug,回答正确率几乎为零,GPT到Llama无一幸免
目录 前言
1.名字和描述颠倒一下,大模型就糊涂了
2.实验及结果
3.未来展望 前言 大模型的逻辑?不存在的。 我让 GPT-3 和 Llama 学会一个简单的知识:A 就是 B,然后反过来问 B 是什么,结果发现 AI 回答的正确率竟然是…
在Redhat 7 Linux上安装llama.cpp [ 错误stdatomic.h: No such file or directory]
前期准备
在github上下载llama.cpp或克隆。
GitHub - ggerganov/llama.cpp: LLM inference in C/C
git clone https://github.com/ggerganov/llama.cpp.gitcd llama.cpp
执行make命令编译llama.cpp
make
在huggingface里下载量化了的 gguf格式的llama2模型。
https:/…
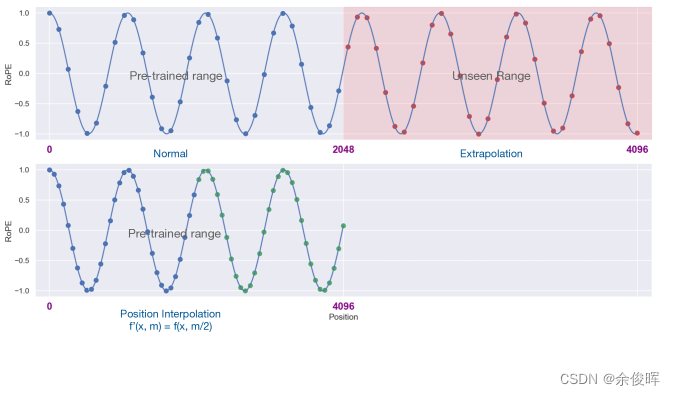
LLaMA长度外推高性价比trick:线性插值法及相关改进源码阅读及相关记录
前言
最近,开源了可商用的llama2,支持长度相比llama1的1024,拓展到了4096长度,然而,相比GPT-4、Claude-2等支持的长度,llama的长度外推显得尤为重要,本文记录了三种网络开源的RoPE改进方式及相…

LLaMA参数微调方法
1.Adapter Tuning:嵌入在transformer中
新增了一个名为adapter的结构,其核心思想是保持模型其他原始参数不变,只改变adapter的参数,其结构如下图所示: 1.在每一个transformer模块最后都加入一层adapter。
2.adapter首…
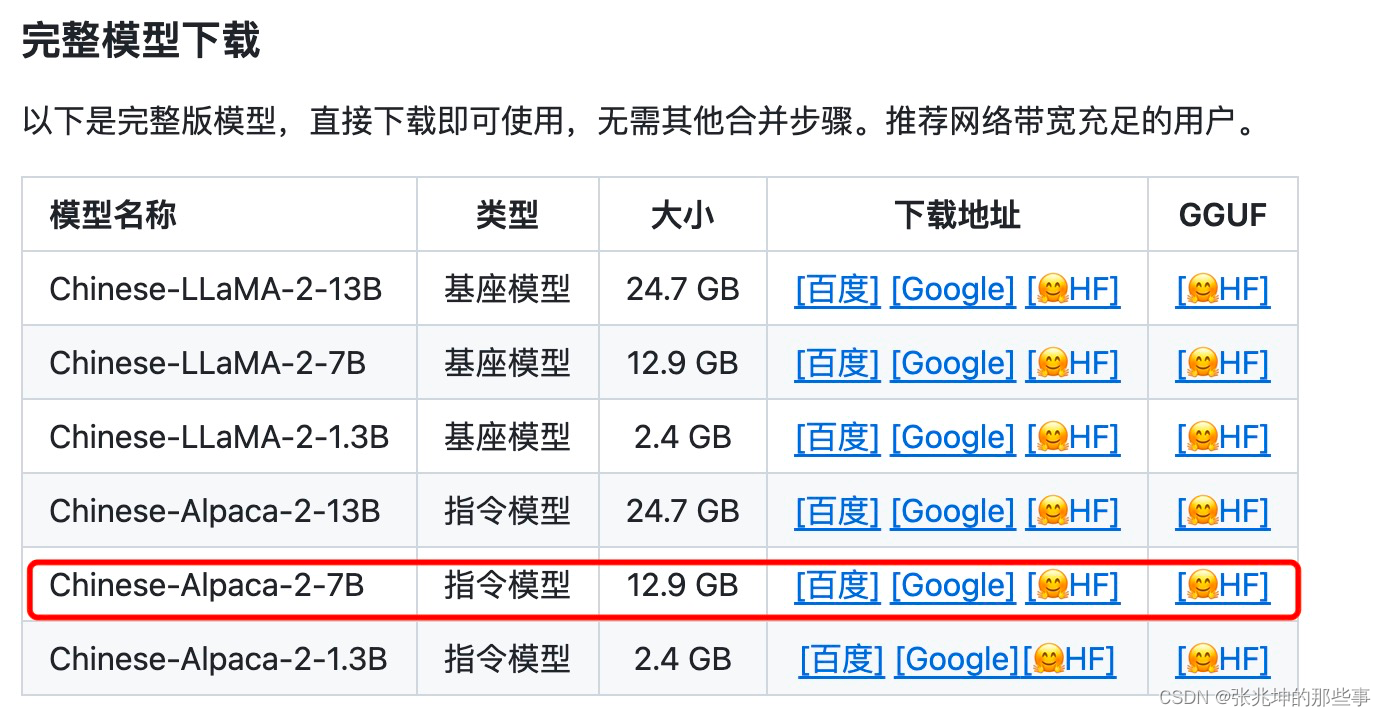
笔记本电脑上部署LLaMA-2中文模型
尝试在macbook上部署LLaMA-2的中文模型的详细过程。
(1)环境准备
MacBook Pro(M2 Max/32G);
VMware Fusion Player 版本 13.5.1 (23298085);
Ubuntu 22.04.2 LTS;
给linux虚拟机分配8*core CPU 16G RAM。
我这里用的是16bit的量化模型,…
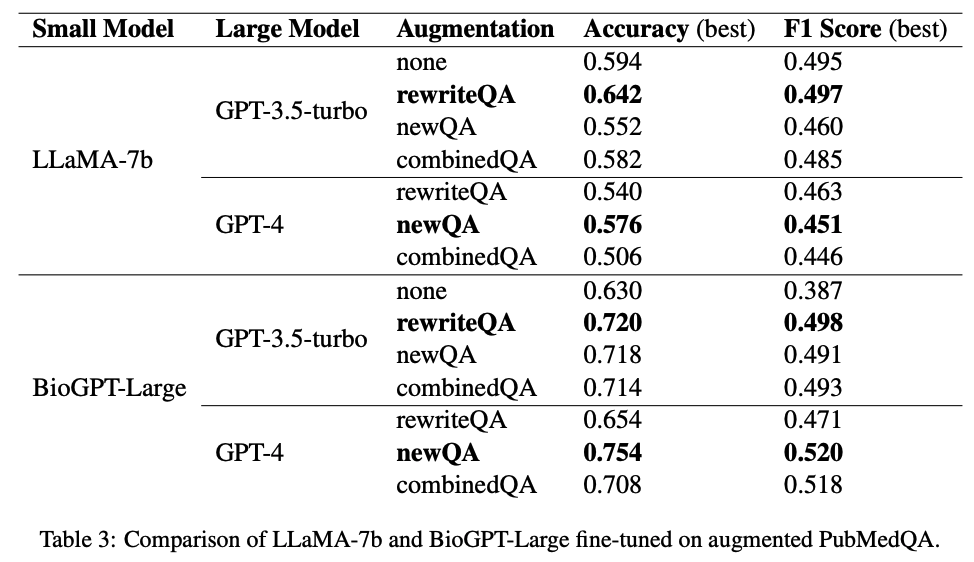
卷起来!Dr. LLaMA:通过生成数据增强改进特定领域 QA 中的小型语言模型,重点关注医学问答任务...
大家好,最近突然发现了一篇在专门应用于医学领域的LLaMA,名为Dr.LLaMA(太卷了太卷了),就此来分享下该语言模型的构建方法和最终的性能情况。 论文:Dr. LLaMA: Improving Small Language Models in Domain-S…
使用 LoRA 技术对 LLaMA 65B 大模型进行微调及推理
前几天,Meta 发布了 LIMA 大模型,在LLaMA-65B的基础上,无需使用 RLHF,只用了 1000 个精心准备的样本数据进行微调,就达到了和 GPT-4 相媲美的程度。这激发了我探索 LLaMA 65B 大模型的兴趣。 之前的一系列大模型相关文…
Chinese-LLaMA-Alpaca-2模型量化部署测试
简介
Chinese-LLaMA-Alpaca-2基于Meta发布的可商用大模型Llama-2开发, 是中文LLaMA&Alpaca大模型的第二期项目.
量化
模型的下载还是应用脚本
bash hfd.sh hfl/chinese-alpaca-2-13b --tool aria2c -x 8应用llama.cpp进行量化, 主要参考该教程. 其中比较折腾的是与BLAS…

Graph RAG: 知识图谱结合 LLM 的检索增强
本文为大家揭示 NebulaGraph 率先提出的 Graph RAG 方法,这种结合知识图谱、图数据库作为大模型结合私有知识系统的最新技术栈,是 LLM 系列的第三篇,加上之前的图上下文学习、Text2Cypher 这两篇文章,目前 NebulaGraph LLM 相关的…
llama.cpp 编译安装@Ubuntu
在Kylin 和Ubuntu编译llama.cpp ,具体参考:llama模型c语言推理FreeBSD-CSDN博客
现在代码并编译:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
mkdir build
cd build
cmake ..
cmake --build . --config Release# 可选…
![[译] DeepSpeed:所有人都能用的超大规模模型训练工具](https://img-blog.csdnimg.cn/img_convert/2366fdf2b3f993aed18c4209c4355d8c.png)
[译] DeepSpeed:所有人都能用的超大规模模型训练工具
我们于今年 2 月份发布了 DeepSpeed。这是一个开源深度学习训练优化库,其中包含的一个新的显存优化技术—— ZeRO(零冗余优化器),通过扩大规模,提升速度,控制成本,提升可用性,极大地…
LLM系列 | 20 : Llama2 实战(下篇)-中文语料微调(附完整代码)
简介
紧接前文:
万字长文细说ChatGPT的前世今生Llama 2实战(上篇):本地部署(附代码)
上篇主要介绍Llama2的基本情况和基于官方模型实测Llama2在中英上的效果,包括单轮和多轮对话。今天这篇小作文作为Llama2的下篇,主要介绍如何用中文语料对…

大模型部署实战(一)——Ziya-LLaMA-13B
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️ 👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…

LLM - LLaMA-2 获取文本向量并计算 Cos 相似度
目录
一.引言
二.获取文本向量
1.hidden_states 与 last_hidden_states
◆ hidden_states
◆ last_hidden_states
2.LLaMA-2 获取 hidden_states
◆ model config
◆ get Embedding
三.获取向量 Cos 相似度
1.向量选择
2.Cos 相似度
3.BERT-whitening 特征白化
…
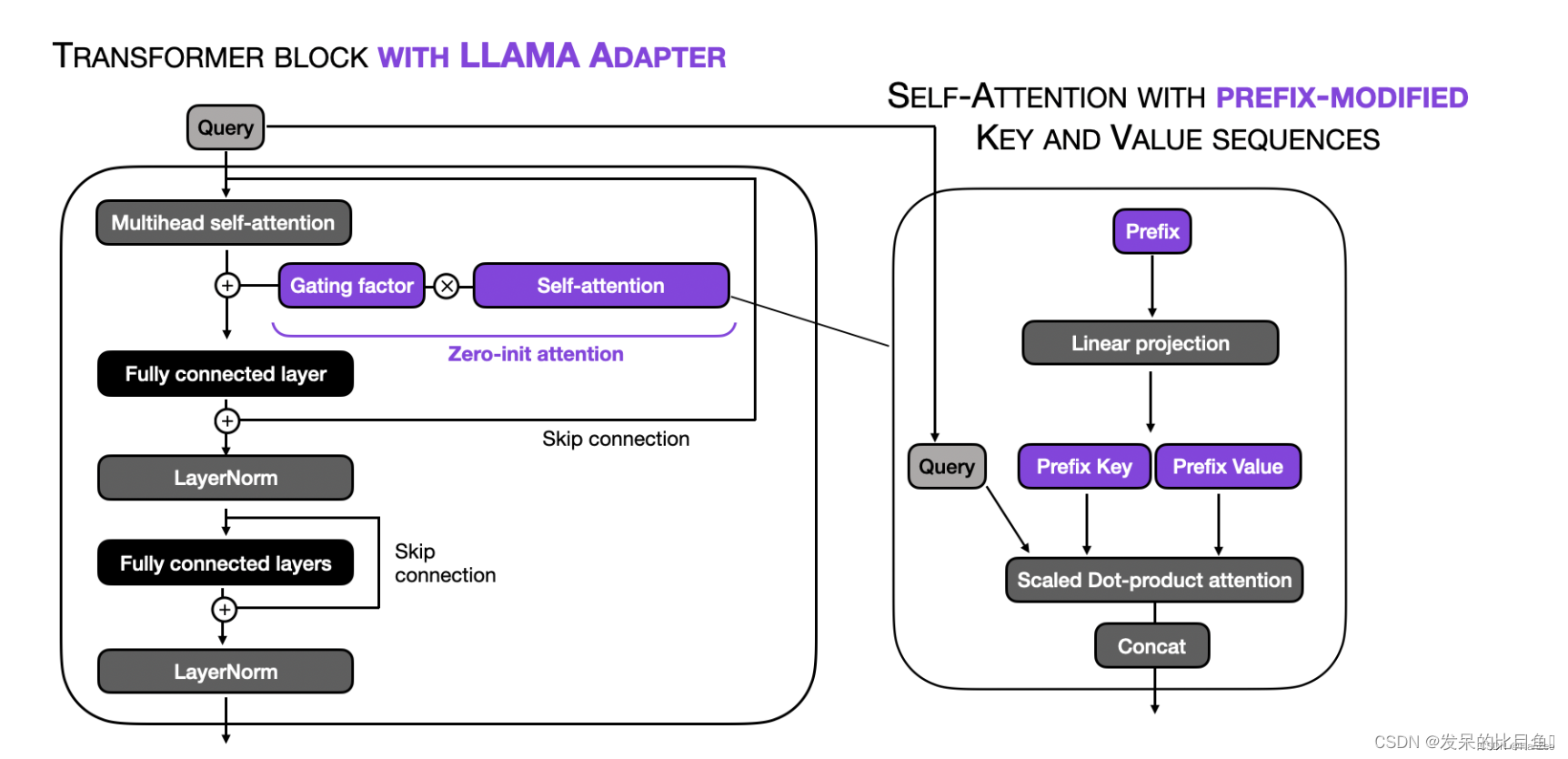
LLaMA-Adapter源码解析
LLaMA-Adapter源码解析 伪代码
def transformer_block_with_llama_adapter(x, gating_factor, soft_prompt):residual xy zero_init_attention(soft_prompt, x) # llama-adapter: prepend prefixx self_attention(x)x x gating_factor * y # llama-adapter: apply zero_init…
一文读懂Llama 2(从原理到实战)
简介
Llama 2,是Meta AI正式发布的最新一代开源大模型。
Llama 2训练所用的token翻了一倍至2万亿,同时对于使用大模型最重要的上下文长度限制,Llama 2也翻了一倍。Llama 2包含了70亿、130亿和700亿参数的模型。Meta宣布将与微软Azure进行合…
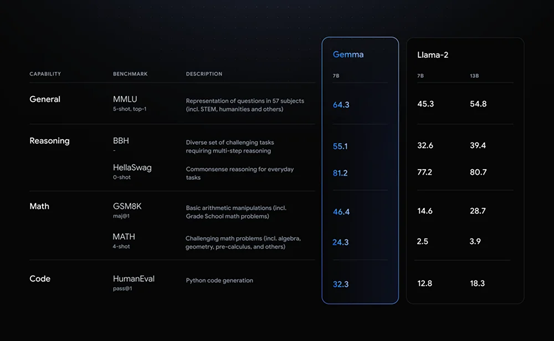
谷歌掀桌子!开源Gemma:可商用,性能超过Llama 2!
2月22日,谷歌在官网宣布,开源大语言模型Gemma。
Gemma与谷歌最新发布的Gemini 使用了同一架构,有20亿、70亿两种参数,每种参数都有预训练和指令调优两个版本。
根据谷歌公布的测试显示,在MMLU、BBH、GSM8K等主流测试…

Mol-Instructions:大模型赋能,药物研发新视野
论文标题:Mol-Instructions: A Large-Scale Biomolecular Instruction Dataset for Large Language Models
论文链接:
https://arxiv.org/pdf/2306.08018.pdf
Github链接:
https://github.com/zjunlp/Mol-Instructions
模型下载…
Llama中文大模型-部署加速
随着大模型参数规模的不断增长,在有限的算力资源下,提升模型的推理速度逐渐变为一个重要的研究方向。常用的推理加速框架包含 lmdeploy、TensorRT-LLM、vLLM和JittorLLMs 等。 TensorRT-LLM
TensorRT-LLM由NVIDIA开发,高性能推理框架 详细的…

使用 Amazon SageMaker 微调 Llama 2 模型
本篇文章主要介绍如何使用 Amazon SageMaker 进行 Llama 2 模型微调的示例。 这个示例主要包括: Llama 2 总体介绍Llama 2 微调介绍Llama 2 环境设置Llama 2 微调训练 前言 随着生成式 AI 的热度逐渐升高,国内外各种基座大语言竞相出炉,在其基础上衍生出…
类ChatGPT项目的部署与微调(上):从LLaMA到Alpaca、Vicuna、BELLE
前言
近期,除了研究ChatGPT背后的各种技术细节 不断看论文(至少100篇,100篇目录见此:ChatGPT相关技术必读论文100篇),还开始研究一系列开源模型(包括各自对应的模型架构、训练方法、训练数据、本地私有化部署、硬件配置要求、微…
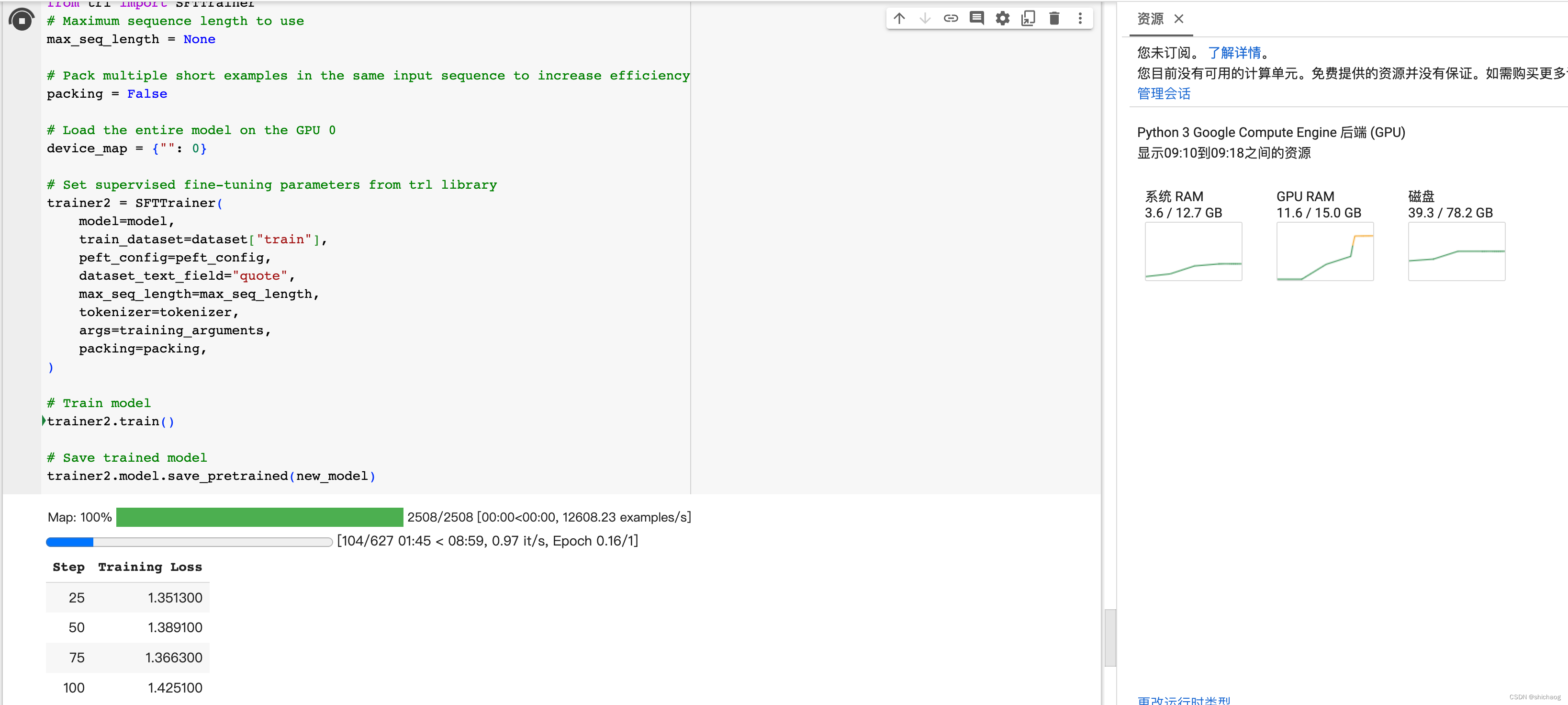
大语言模型之七- Llama-2单GPU微调SFT
(T4 16G)模型预训练colab脚本在github主页面。详见Finetuning_LLama_2_0_on_Colab_with_1_GPU.ipynb
在上一篇博客提到两种改进预训练模型性能的方法Retrieval-Augmented Generation (RAG) 或者 finetuning。本篇博客过一下模型微调。
微调:…
第四节课 XTuner 大模型单卡低成本微调实战 作业
文章目录 笔记作业 笔记
XTuner 大模型单卡低成本微调原理:https://blog.csdn.net/m0_49289284/article/details/135532140XTuner 大模型单卡低成本微调实战:https://blog.csdn.net/m0_49289284/article/details/135534817
作业
基础作业:…
Meta开源Code Llama 70B,缩小与GPT-4之间的技术鸿沟
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…

Mistral 7B 比Llama 2更好的开源大模型 (三)
Mistral 7B 比Llama 2更好的开源大模型 Mistral 7B是一个70亿参数的语言模型,旨在获得卓越的性能和效率。Mistral 7B在所有评估的基准测试中都优于最好的开放13B模型(Llama 2),在推理、数学和代码生成方面也优于最好的发布34B模型(Llama 1)。Mistral 7B模型利用分组查询注…
国内外大模型收录列表
时间截止:2023-09-08,数据来源:https://github.com/wgwang/LLMs-In-China。
从收录可以看出开源大模型基座选用:LLaMA>BLOOM>ChatGLM2
国内大模型列表
序号公司大模型省市类别官网说明1百度文心一言,灵医Bot北京通用…
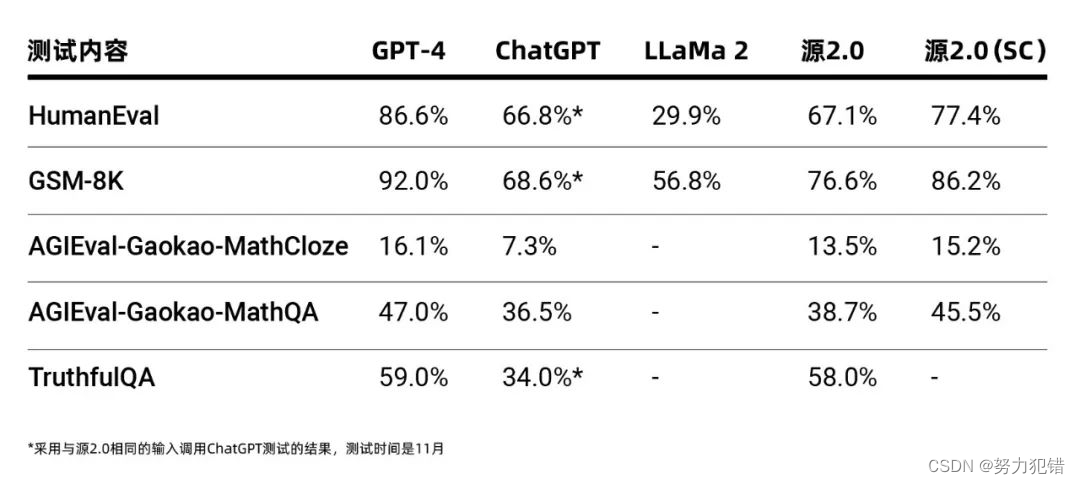
浪潮信息大突破:全面开源1026亿参数模型源2.0
近日,浪潮信息发布了一项重大成就,宣布全面开源其1026亿参数的基础大模型——源2.0。该举措在AI产业界引起了广泛关注,被视为推动生成式人工智能产业快速发展的关键一步。
源2.0模型概览
源2.0是一个多参数级别的大模型,提供了1…
本地训练中文LLaMA模型实战教程,民间羊驼模型,24G显存盘它!
学习目录
1本地部署中文LLaMA模型实战教程,民间羊驼模型 2本地预训练中文LLaMA模型实战教程,民间羊驼模型(本博客) 3 精调训练中文LLaMA模型实战教程,民间羊驼模型(马上发布)
简介
在学习完上篇【1本地部署中文LLaMA模型实战教程,民间羊驼模型】后,我们已经学会了下…

AI工程师招募;60+开发者AI工具清单;如何用AI工具读懂插件源码;开发者出海解读;斯坦福LLM课程 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🤖 一则AI工程师招募信息:新领域需要新技能 Vision Flow (目的涌现) 是一家基于 AGI 原生技术的创业公司,是全球探…
![[论文笔记]LLaMA: Open and Efficient Foundation Language Models](https://img-blog.csdnimg.cn/img_convert/5438e10bf23516a6eb5033737338c247.png)
[论文笔记]LLaMA: Open and Efficient Foundation Language Models
引言
今天带来经典论文 LLaMA: Open and Efficient Foundation Language Models 的笔记,论文标题翻译过来就是 LLaMA:开放和高效的基础语言模型。
LLaMA提供了不可多得的大模型开发思路,为很多国产化大模型打开了一片新的天地,论文和代码值…
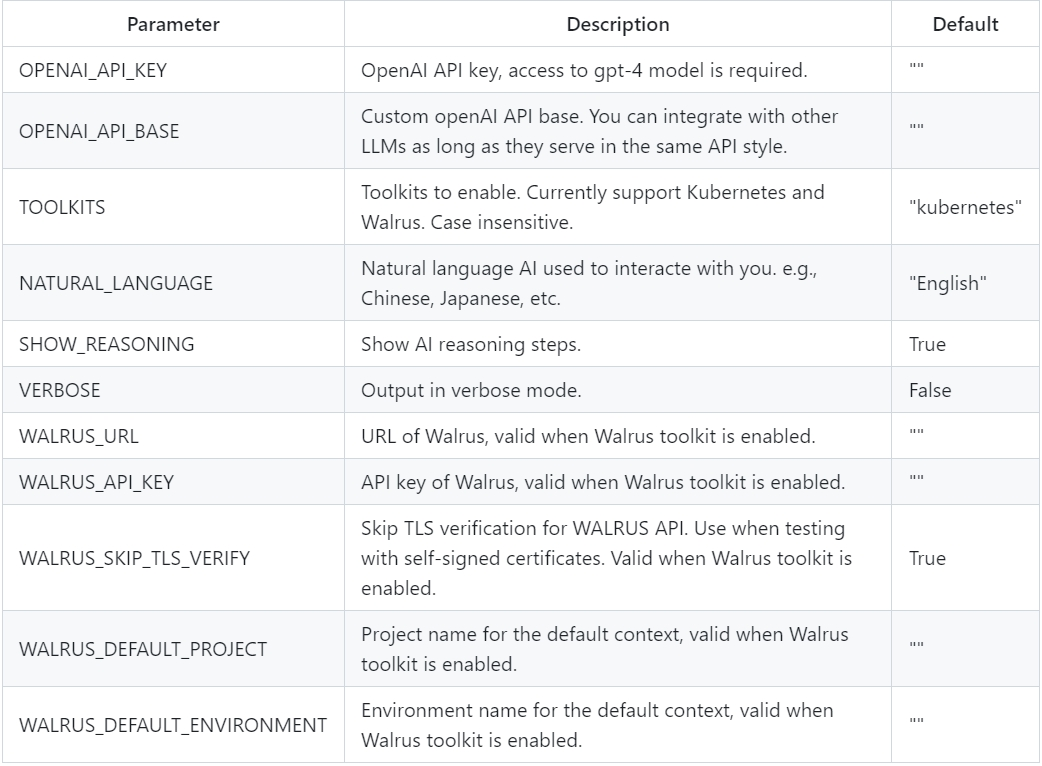
使用 Appilot 部署 Llama2,会聊天就行!
Walrus 是一款基于平台工程理念的应用管理平台,致力于解决应用交付领域的深切痛点。借助 Walrus 将云原生的能力和最佳实践扩展到非容器化环境,并支持任意应用形态统一编排部署,降低使用基础设施的复杂度,为研发和运维团队提供易用…

Llama 2 论文《Llama 2: Open Foundation and Fine-Tuned Chat Models》阅读笔记
文章目录 Llama 2: Open Foundation and Fine-Tuned Chat Models1.简介2.预训练2.1 预训练数据2.2 训练详情2.3 LLAMA 2 预训练模型评估 3. 微调3.1 supervised Fine-Tuning(SFT)3.2 Reinforcement Learning with Human Feedback (RLHF)3.2.1 人类偏好数据收集3.2.2 奖励模型训…
MetaGPT前期准备与快速上手
大家好,MetaGPT 是基于大型语言模型(LLMs)的多智能体协作框架,GitHub star数量已经达到31.3k。 接下来我们聊一下快速上手 这里写目录标题 一、环境搭建1.python 环境2. MetaGpt 下载 二、MetaGPT配置1.调用 ChatGPT API 服务2.简…
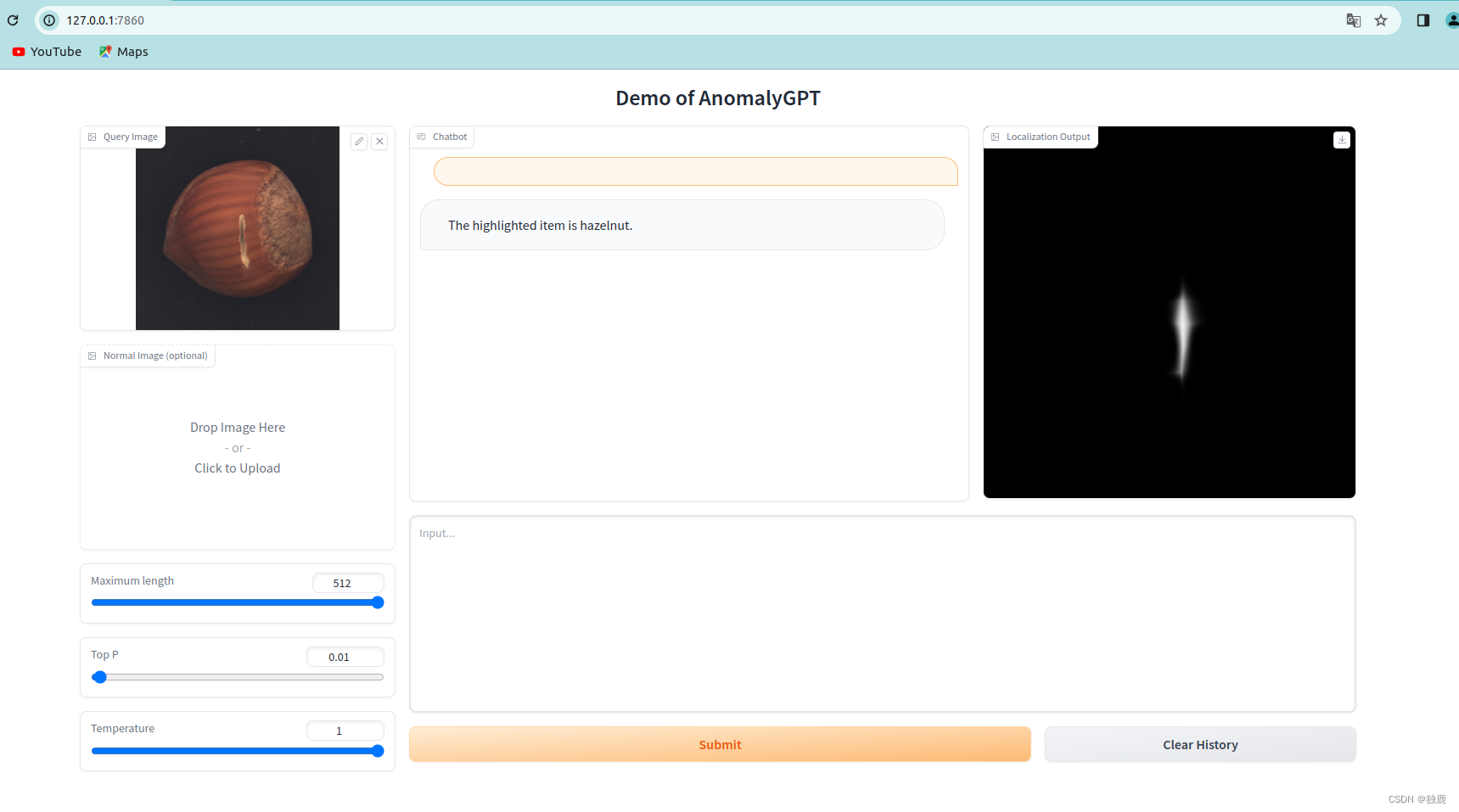
工业异常检测AnomalyGPT-Demo试跑
写在前面:如果你有大的cpu和gpu可以使用,直接根据官方的安装说明就可以,如果没有,可以点进来试着看一下我个人的安装经验。
一、试跑环境
NVIDIA4090显卡24g,cpu内存33G,交换空间8g,操作系统ubuntu22.04(试跑过程cpu…

Llama2通过llama.cpp模型量化 WindowsLinux本地部署
Llama2通过llama.cpp模型量化 Windows&Linux本地部署
什么是LLaMA 1 and 2
LLaMA,它是一组基础语言模型,参数范围从7B到65B。在数万亿的tokens上训练的模型,并表明可以专门使用公开可用的数据集来训练最先进的模型,而无需求…
lag-llama源码解读(Lag-Llama: Towards Foundation Models for Time Series Forecasting)
Lag-Llama: Towards Foundation Models for Time Series Forecasting 文章内容: 时间序列预测任务,单变量预测单变量,基于Llama大模型,在zero-shot场景下模型表现优异。创新点,引入滞后特征作为协变量来进行预测。 获得…

探索LLaMA模型:架构创新与Transformer模型的进化之路
引言
在人工智能和自然语言处理领域,预训练语言模型的发展一直在引领着前沿科技的进步。Meta AI(前身为Facebook)在2023年2月推出的LLaMA(Large Language Model Meta AI)模型引起了广泛关注。LLaMA模型以其独特的架构…
Llama-2 推理和微调的硬件要求总结:RTX 3080 就可以微调最小模型
大语言模型微调是指对已经预训练的大型语言模型(例如Llama-2,Falcon等)进行额外的训练,以使其适应特定任务或领域的需求。微调通常需要大量的计算资源,但是通过量化和Lora等方法,我们也可以在消费级的GPU上…
Chinese-LLaMA-AIpaca 指令精调
文章目录 一、继续训练 Chinese-AIpaca 模型的 LoRA权重二、基于中文Chinese-LLaMA训练全新的指令精调LoRA权重1、合并2、基于中文 Chinese-LLaMA 训练全新的指令精调 LoRA权重一、继续训练 Chinese-AIpaca 模型的 LoRA权重 下载数据集 alpaca_data_zh_51k.json https://github…
LLaMA-2 简介:开源大型语言模型的新篇章
LLaMA-2 简介:开源大型语言模型的新篇章
LLaMA-2 是一款领先的开源大型语言模型(LLM),其参数规模从 7 亿到 70 亿不等。与先前的版本相比,LLaMA-2 通过预训练更多数据、使用更长的上下文长度和采用优化快速推理的架构…
大模型学习与实践笔记(十)
一、模型测评的意义 二、如何对模型进行测评 三、OpenCompass 评测流水线设计 四、大模型评测带来的挑战 五、OpenCompass 评测示例
1.多模态
优势:
1.基于感知与推理,将评估维度逐级细分
2.约3000 道单选题,覆盖目标检测,文本…

【 书生·浦语大模型实战营】学习笔记(一):全链路开源体系介绍
🎉AI学习星球推荐: GoAI的学习社区 知识星球是一个致力于提供《机器学习 | 深度学习 | CV | NLP | 大模型 | 多模态 | AIGC 》各个最新AI方向综述、论文等成体系的学习资料,配有全面而有深度的专栏内容,包括不限于 前沿论文解读、…

Koala:加州大学BAIR团队使用ChatGPT蒸馏数据和公开数据集微调LLaMA模型得到
自从Meta发布LLaMA以来,围绕它开发的模型与日俱增,比如Alpaca、llama.cpp、ChatLLaMA以及Vicuna等等,相关的博客可以参考如下:
【Alpaca】斯坦福发布了一个由LLaMA 7B微调的模型Alpaca(羊驼),训…

ChatGPT全球最大开源平替OpenAssistant:基于Pythia和LLaMA微调而来
论文地址:https://drive.google.com/file/d/10iR5hKwFqAKhL3umx8muOWSRm7hs5FqX/view 项目地址:https://github.com/LAION-AI/Open-Assistant 数据集地址:https://huggingface.co/datasets/OpenAssistant/oasst1 体验地址:http…
LLaMA-Factory微调ChatGLM3报错: Segmentation fault (core dumped)
SFT训练模型的命令
CUDA_VISIBLE_DEVICES0 python src/train_bash.py \--stage sft \--model_name_or_path models/chatglm3-6b \--do_train \--dataset self_cognition \--template chatglm3 \--finetuning_type lora \--lora_target query_key_value \--output_dir output/c…
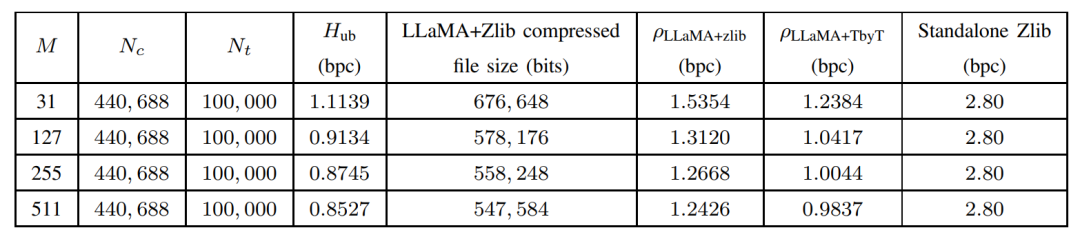
大模型入局传统算法,LLMZip基于LLaMA-7B实现1MB文本压缩率90%!
论文链接: https://arxiv.org/abs/2306.04050 随着以ChatGPT、GPT-4为代表的AI大模型逐渐爆火进入公众视野,各行各业都开始思考如何更好的使用和发展自己的大模型,有一些评论甚至认为大模型是以人工智能为标志的第四次产业革命的核心竞争产品…
探索Code Llama 70B:Meta让AI辅助编程更易获得的举措
探索Code Llama 70B:Meta让AI辅助编程更易获取
在AI技术不断改变软件开发的今天,Meta推出了其最先进的开源基础模型,简化了软件开发流程。这个模型名为Code Llama 70B,旨在让AI辅助代码生成及其相关任务更容易被更广泛的受众获取…

论文笔记--Goat: Fine-tuned LLaMA Outperforms GPT-4 on Arithmetic Tasks
论文笔记--Goat: Fine-tuned LLaMA Outperforms GPT-4 on Arithmetic Tasks 1. 文章简介2. 文章概括3 文章重点技术3.1 LLM的选择3.2 算数任务的可学习性(learnability)3.3 大模型的加减乘除 4. 数值实验结果5. 文章亮点6. 原文传送门7. References 1. 文章简介
标题ÿ…

关于 Llama 2 的一切资源,我们都帮你整理好了
Llama 2 是一个由 Meta 开发的大型语言模型,是 LLaMA 1 的继任者。Llama 2 可通过 AWS、Hugging Face 获取,并可以自由用于研究和商业用途。Llama 2 预训练模型在 2 万亿个标记上进行训练,相比 LLaMA 1 的上下文长度增加了一倍。它的微调模型…

LlamaGPT -基于Llama 2的自托管类chatgpt聊天机器人
LlamaGPT一个自托管、离线、类似 ChatGPT 的聊天机器人,由 Llama 2 提供支持。100% 私密,不会有任何数据离开你的设备。 推荐:用 NSDT编辑器 快速搭建可编程3D场景 1、如何安装LlamaGPT
LlamaGPT可以安装在任何x86或arm64系统上。
首先确保…
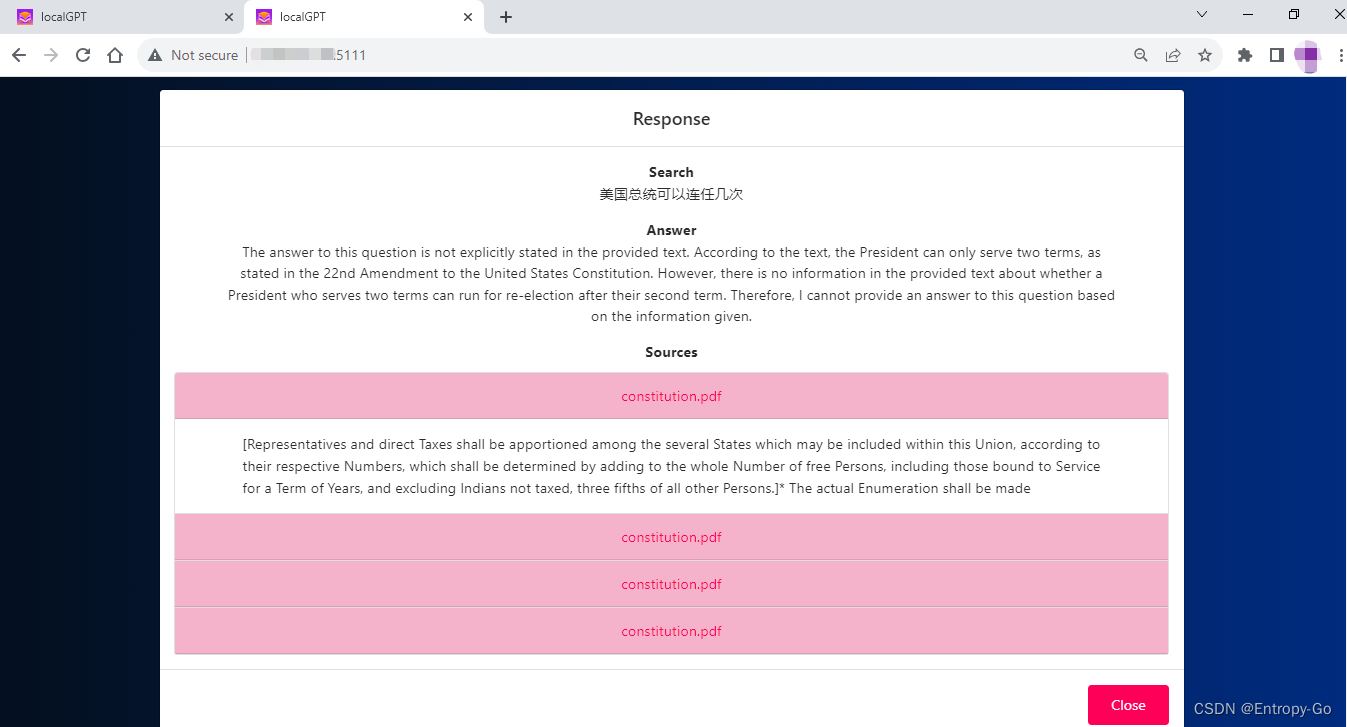
基于Llama2和LangChain构建本地化定制化知识库AI聊天机器人
参考:
本项目 https://github.com/PromtEngineer/localGPT
模型 https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML
云端知识库项目:基于GPT-4和LangChain构建云端定制化PDF知识库AI聊天机器人_Entropy-Go的博客-CSDN博客
1. 摘要 相比OpenAI的…
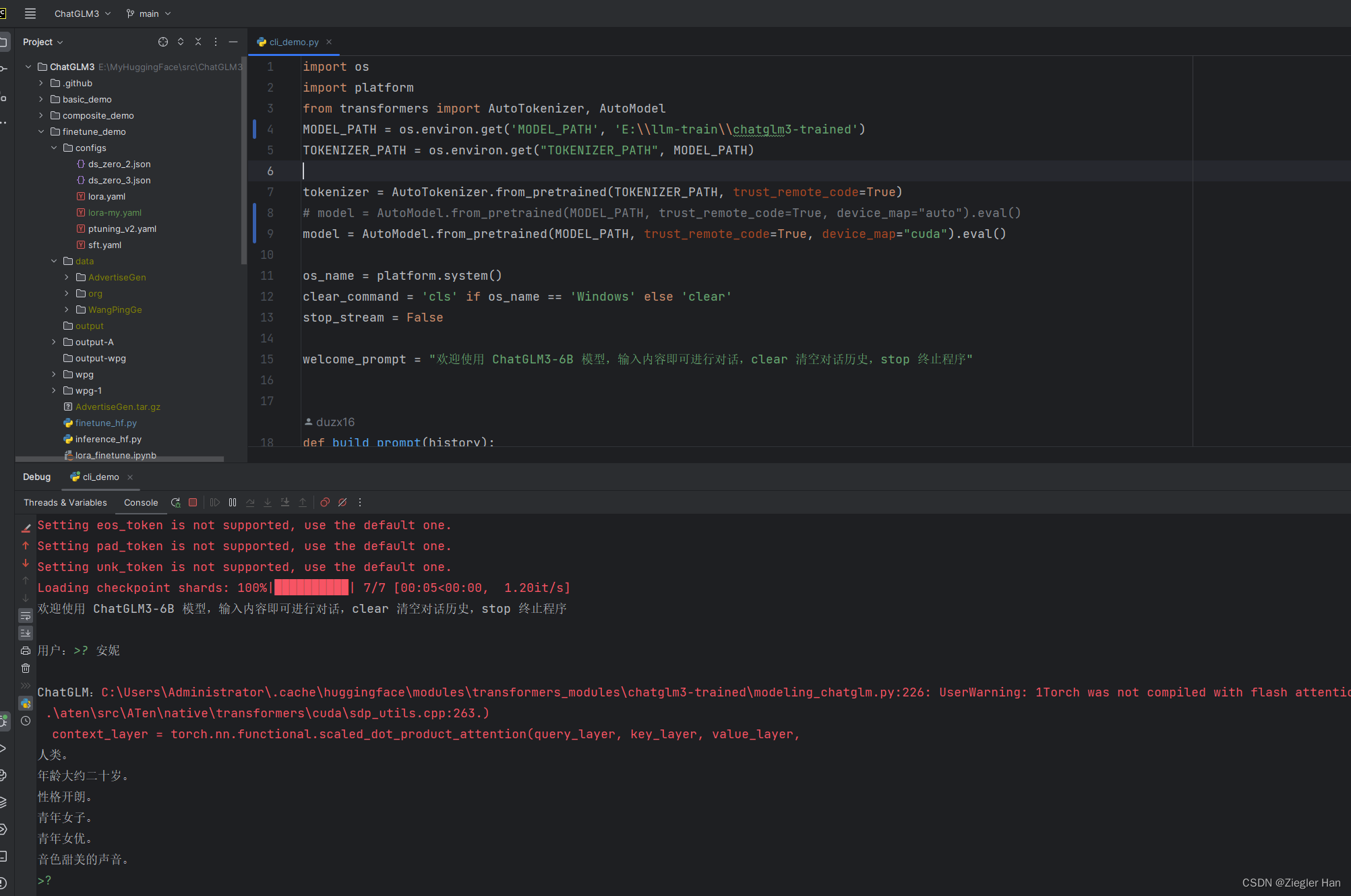
LLaMA-Factory微调(sft)ChatGLM3-6B保姆教程
LLaMA-Factory微调(sft)ChatGLM3-6B保姆教程
准备
1、下载
下载LLaMA-Factory下载ChatGLM3-6B下载ChatGLM3windows下载CUDA ToolKit 12.1 (本人是在windows进行训练的,显卡GTX 1660 Ti)
CUDA安装完毕后,…
群晖NAS使用Docker部署大语言模型Llama 2结合内网穿透实现公网访问本地GPT聊天服务
文章目录 1. 拉取相关的Docker镜像2. 运行Ollama 镜像3. 运行Chatbot Ollama镜像4. 本地访问5. 群晖安装Cpolar6. 配置公网地址7. 公网访问8. 固定公网地址 随着ChatGPT 和open Sora 的热度剧增,大语言模型时代,开启了AI新篇章,大语言模型的应用非常广泛,包括聊天机…
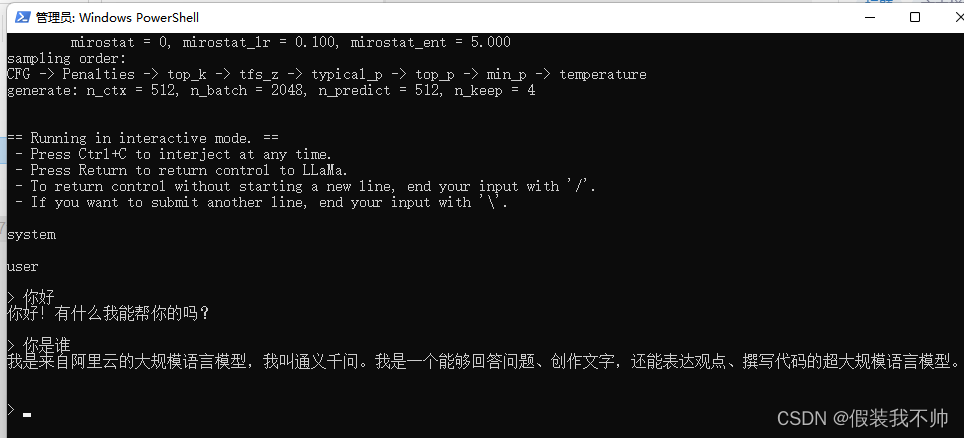
llama.cpp运行qwen0.5B
编译llama.cp
参考
下载模型
05b模型下载
转化模型
创建虚拟环境
conda create --prefixD:\miniconda3\envs\llamacpp python3.10
conda activate D:\miniconda3\envs\llamacpp安装所需要的包 cd G:\Cpp\llama.cpp-master
pip install -r requirements.txt
python conver…
LLaMA-Factory+qwen多轮对话微调
LLaMA-Factory地址:https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md
qwen地址:https://huggingface.co/Qwen/Qwen-7B-Chat/tree/main
数据准备
数据样例
[
{"id": "x3959", "conversations": [{&qu…
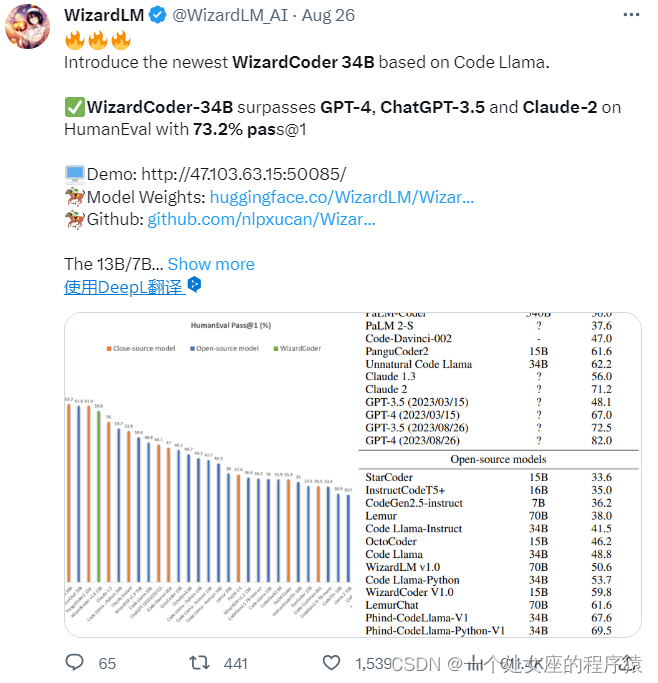
LLMs之Code:Code Llama的简介、安装、使用方法之详细攻略
LLMs之Code:Code Llama的简介、安装、使用方法之详细攻略 导读:2023年08月25日(北京时间),Meta发布了Code Llama,一个可以使用文本提示生成代码的大型语言模型(LLM)。Code Llama是最先进的公开可用的LLM代码任务,并有潜…
书生·浦语大模型趣味Demo作业( 第二节课)第二期
文章目录 基础作业进阶作业 基础作业 进阶作业 熟悉 huggingface 下载功能,使用 huggingface_hub python 包,下载 InternLM2-Chat-7B 的 config.json 文件到本地(需截图下载过程) 完成 浦语灵笔2 的 图文创作 及 视觉问答 部署&…

【记录】LangChain|llama 2速通版
官方教程非常长,我看了很认可,但是看完了之后呢就需要一些整理得当的笔记让我自己能更快地找到需求。所以有了这篇文章。【写给自己看的,里面半句废话的解释都没有,如果看不懂的话直接看官方教程再看我的】
我是不打算一开始就用…
2024 Linux(centOS7) 下安装 Docker -- Docker中运行ollama模型
首先进入docker中运行以下命令: 安装yum-utils
yum install -y yum-utils device-mapper-persistent-data lvm2 --skip-broken
更换下载源为:阿里云
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.r…

【记录】LangChain|Ollama结合LangChain使用的速通版(包含代码以及切换各种模型的方式)
官方教程非常长,我看了很认可,但是看完了之后呢就需要一些整理得当的笔记让我自己能更快地找到需求。所以有了这篇文章。【写给自己看的,里面半句废话的解释都没有,如果看不懂的话直接看官方教程再看我的】
我是不打算一开始就用…
Anthropic Claude 3 加入亚马逊云科技 AI“全家桶”
编辑 | 宋慧
出品 | CSDN AIGC 每天都有新动态发生。最新的消息是亚马逊在 3 月底完成了对 Anthropic 的 40 亿美元投资(也是亚马逊 30 年来最大一笔外部投资),以及 GPT-4 最强对手的 Anthropic Claude 3 已经在亚马逊云科技 Amazon Bedrock…

Llama.cpp工具main使用手册
Llama.cpp提供的 main工具允许你以简单有效的方式使用各种 LLaMA 语言模型。 它专门设计用于与 llama.cpp 项目配合使用。 推荐:用 NSDT编辑器 快速搭建可编程3D场景 Llama.cpp的工具 main提供简单的 C/C 实现,具有可选的 4 位量化支持,可实现…

Mistral 7B 比Llama 2更好的开源大模型 (二)
Mistral 7B 论文学习
Mistral 7B
论文链接 https://arxiv.org/abs/2310.06825 代码: https://github.com/mistralai/mistral-src 网站: https://mistral.ai/news/announcing-mistral-7b/ 论文摘要
Mistral 7B是一个70亿参数的语言模型,旨在获得卓越的性能和效率。Mistral 7…
Code Llama: Open Foundation Models for Code
本文是LLM系列文章,针对《Code Llama: Open Foundation Models for Code》的翻译。 Code Llama:代码的开放基础模型 摘要1 引言2 Code Llama:专业化Llama2用于代码3 结果4 负责任的人工智能与安全5 相关工作6 讨论 摘要
我们发布了Code Lla…

Mistral 7B 比Llama 2更好的开源大模型 (四)
Mistral 7B在平衡高性能和保持大型语言模型高效的目标方面迈出了重要的一步。通过我们的工作,我们的目标是帮助社区创建更实惠、更高效、更高性能的语言模型,这些模型可以在广泛的现实世界应用程序中使用。
Mistral 7B在实践中,对于16K和W=4096的序列长度,对FlashAttentio…
【个人开发】llama2部署实践(一)——基于CPU部署
1. Anaconda安装
mkdir -p /opt/anaconda
cd /opt/anaconda
# 参考链接:https://repo.anaconda.com/archive/index.html
wget https://repo.anaconda.com/archive/Anaconda3-2023.07-2-Linux-x86_64.sh
sh Anaconda3-2023.07-2-Linux-x86_64.sh2.安装git
yum inst…

Danswer 接入 Llama 2 模型 | 免费在 Google Colab 上托管 Llama 2 API
一、前言
前面在介绍本地部署免费开源的知识库方案时,已经简单介绍过 Danswer《Danswer 快速指南:不到15分钟打造您的企业级开源知识问答系统》,它支持即插即用不同的 LLM 模型,可以很方便的将本地知识文档通过不同的连接器接入到…
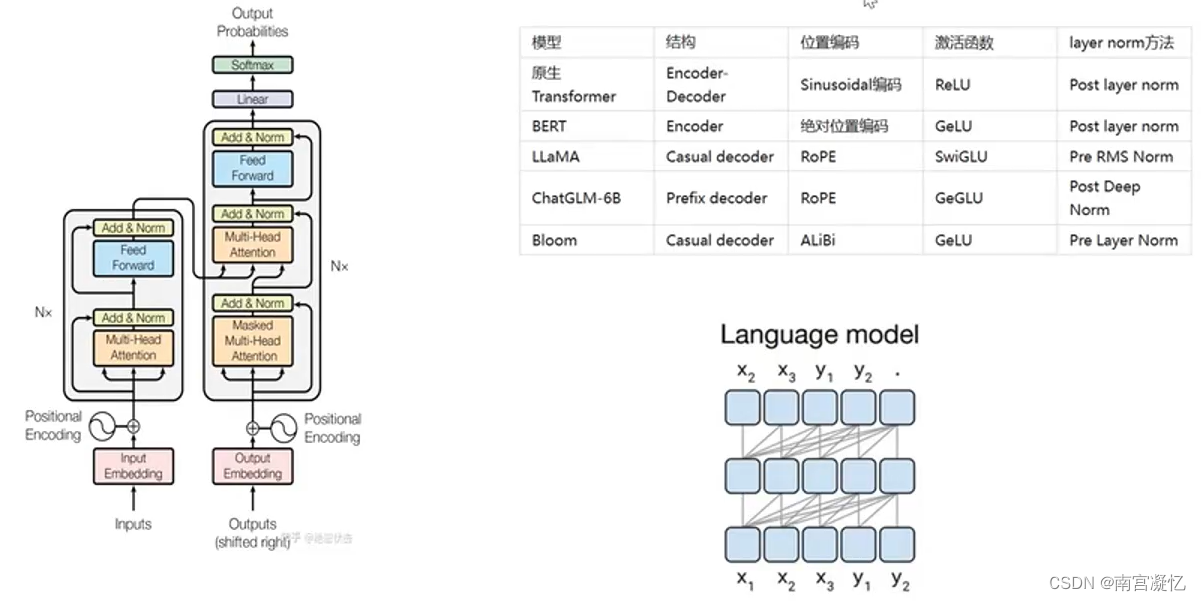
羊驼系列大模型LLaMa、Alpaca、Vicuna
羊驼系列大模型:大模型的安卓系统
GPT系列:类比ios系统,不开源
LLaMa让大模型平民化
LLaMa优势
用到的数据:大部分英语、西班牙语,少中文 模型下载地址
https://huggingface.co/meta-llama Alpaca模型
Alpaca是斯…
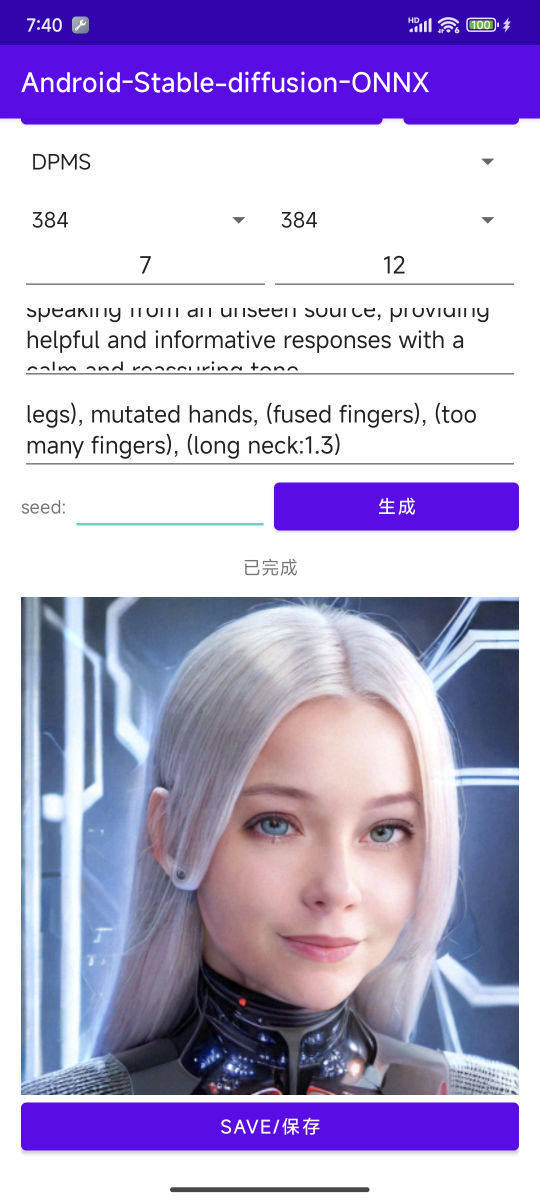
使用搭载骁龙 8 Gen 3 的安卓手机运行 AI 大模型
本篇文章聊聊,在 Android 手机上简单运行 AI 大模型的方法,来体验英文语言模型(Llama2 7B、Mistral 7B、RedPajama 3B、Google Gemma 2B、Microsoft PHI 2B);中文语言模型(面壁 MiniCPM、多模态模型&#x…
开启想象翅膀:轻松实现文本生成模型的创作应用,支持LLaMA、ChatGLM、UDA、GPT2、Seq2Seq、BART、T5、SongNet等模型,开箱即用
开启想象翅膀:轻松实现文本生成模型的创作应用,支持LLaMA、ChatGLM、UDA、GPT2、Seq2Seq、BART、T5、SongNet等模型,开箱即用 TextGen: Implementation of Text Generation models
1.介绍
TextGen实现了多种文本生成模型,包括&a…
StackLLaMA: A hands-on guide to train LLaMA with RLHF
Paper name
StackLLaMA: A hands-on guide to train LLaMA with RLHF
Paper Reading Note
Project URL: https://huggingface.co/blog/stackllama Code URL: https://huggingface.co/docs/trl/index
TL;DR
Huggingface 公司开发的 RLHF 训练代码,已集成到 hugg…
借助知识图谱和Llama-Index实现基于大模型的RAG
背景
幻觉是在处理大型语言模型(LLMs)时常见的问题。LLMs生成流畅连贯的文本,但经常产生不准确或不一致的信息。防止LLMs中出现幻觉的一种方法是使用外部知识源,如提供事实信息的数据库或知识图谱。
矢量数据库和知识图谱使用不…
在Windows或Mac上安装并运行LLAMA2
LLAMA2在不同系统上运行的结果
LLAMA2 在windows 上运行的结果 LLAMA2 在Mac上运行的结果 安装Llama2的不同方法
方法一: 编译 llama.cpp
克隆 llama.cpp
git clone https://github.com/ggerganov/llama.cpp.git
通过conda 创建或者venv. 下面是通过conda 创建…

Meta语言模型LLaMA解读:模型的下载部署与运行代码
文章目录 llama2体验地址模型下载下载步骤准备工作什么是Git LFS下载huggingface模型 模型运行代码 llama2
Meta最新语言模型LLaMA解读,LLaMA是Facebook AI Research团队于2023年发布的一种语言模型,这是一个基础语言模型的集合。
体验地址
体验地址 …

在 Mac M1 上运行 Llama 2 并进行训练
在 Mac M1 上运行 Llama 2 并进行训练 Llama 2 是由领先的人工智能研究公司 Meta (前Facebook)开发并发布的下一代大型语言模型 (LLM)。 它基于 2 万亿个公共数据 token 进行了预训练,旨在帮助开发人员和企业组织构建基于人工智能的生成工具和…

LLMs模型速览(GPTs、LaMDA、GLM/ChatGLM、PaLM/Flan-PaLM、BLOOM、LLaMA、Alpaca)
文章目录 一、 GPT系列1.1 GPTs(OpenAI,2018——2020)1.2 InstructGPT(2022-3)1.2.1 算法1.2.2 损失函数 1.3 ChatGPT(2022.11.30)1.4 ChatGPT plugin1.5 GPT-4(2023.3.14࿰…

基于 LLaMA 和 LangChain 实践本地 AI 知识库
有时候,我难免不由地感慨,真实的人类世界,本就是一个巨大的娱乐圈,即使是在英雄辈出的 IT 行业。数日前,Google 正式对外发布了 Gemini 1.5 Pro,一个建立在 Transformer 和 MoE 架构上的多模态模型。可惜,这个被 Google 寄予厚望的产品并未激起多少水花,因为就在同一天…

【关注】国内外经典大模型(ChatGPT、LLaMA、Gemini、DALL·E、Midjourney、文心一言、千问等
以ChatGPT、LLaMA、Gemini、DALLE、Midjourney、Stable Diffusion、星火大模型、文心一言、千问为代表AI大语言模型带来了新一波人工智能浪潮,可以面向科研选题、思维导图、数据清洗、统计分析、高级编程、代码调试、算法学习、论文检索、写作、翻译、润色、文献辅助…
Java-langchain:在Java环境中构建强大的基于LLM的应用程序
Java-langchain: 一个Java 8的LangChain实现。在(企业)Java环境中构建强大的基于LLM的应用程序。
这里持续连载详细的Java入门的LLM学习课程。课程分四个部分:
面向开发者的提示工程 (promptdevelopment)搭建基于 ChatGPT 的问答系统 (chagptapi)使用 LangChain 开…
高效底座模型LLaMA
论文标题:LLaMA: Open and Efficient Foundation Language Models 论文链接:https://arxiv.org/abs/2302.13971 论文来源:Meta AI 一、概述 大型语言模型(Large Languages Models,LLMs)通过大规模文本数据的…
LLM:LLaMA模型和微调的Alpaca模型
待写
LLaMA模型
论文原文:https://arxiv.org/abs/2302.13971v1
预训练数据 模型架构
模型就是用的transformer的decoder,所以在结构上它与GPT是非常类似的,只是有一些细节需要注意一下。
1、RMS Pre-Norm 2、SwiGLU激活函数 3、RoPE旋转位置编码 Alpaca模型 [Stanford …
安卓通过termux部署ChatGLM
一、安装Termux并进行相关配置
1、安装termux
Termux 是一个 Android 终端仿真应用程序,用于在 Android 手机上搭建一个完整的 Linux 环境。 不需要 root 权限 Termux 就可以正常运行。Termux 基本实现 Linux 下的许多基本操作。可以使用 Termux 安装 python&…
从零开始的LLaMA-Factory的指令增量微调
大模型相关目录
大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容 从0起步,扬帆起航。
大模型应用向开发路径及一点个人思考大模型应用开发实用开源项目汇总大模型问答项目…
【AI】实现在本地Mac,Windows和Mobile上运行Llama2模型
【AI】实现在本地Mac,Windows和Mobile上运行Llama2模型 目录 【AI】实现在本地Mac,Windows和Mobile上运行Llama2模型**Llama 2模型是什么?****技术规格和能力****Llama 2中的专门模型****在人工智能开发中的意义****如何在本地使用Llama 2运行Llama.cpp****Llama.cpp的设置*…
from_pretrained 做了啥
transformers的三个核心抽象类是Config, Tokenizer和Model,这些类根据模型种类的不同,派生出一系列的子类。构造这些派生类的对象也很简单,transformers为这三个类都提供了自动类型,即AutoConfig, AutoTokenizer和AutoModel。三个…
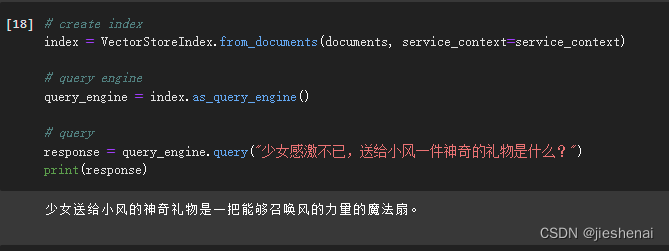
llama-index 结合chatglm3-6B 利用RAG 基于文档智能问答
简介
llamaindex结合chatglm3使用
import os
import torch
from llama_index.core import VectorStoreIndex, ServiceContext
from llama_index.core.callbacks import CallbackManager
from llama_index.core.llms.callbacks import llm_completion_callback
from llama_ind…
Ollama部署在线ai聊天
概述:虽然ollama在Windows方面还有很多bug,但不妨碍它在ai领域上面的成就
第一步:安装Ollama
官网:Download Ollama on Windows 下载安装即可。说明一下ollama的安装位置只能是c盘,好像改不了,但是数据模…
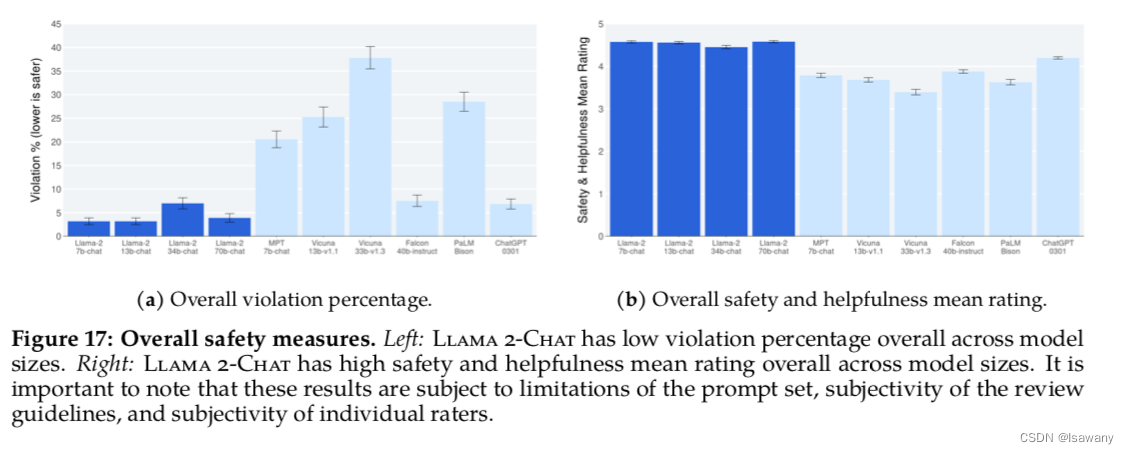
论文笔记--Llama 2: Open Foundation and Fine-Tuned Chat Models
论文笔记--Llama 2: Open Foundation and Fine-Tuned Chat Models 1. 文章简介2. 文章概括3 文章重点技术3.1 预训练Pretraining3.1.1 预训练细节3.1.2 Llama2模型评估 3.2 微调Fine-tuning3.2.1 Supervised Fine-Tuning(FT)3.2.2 Reinforcement Learning with Human Feedback(…
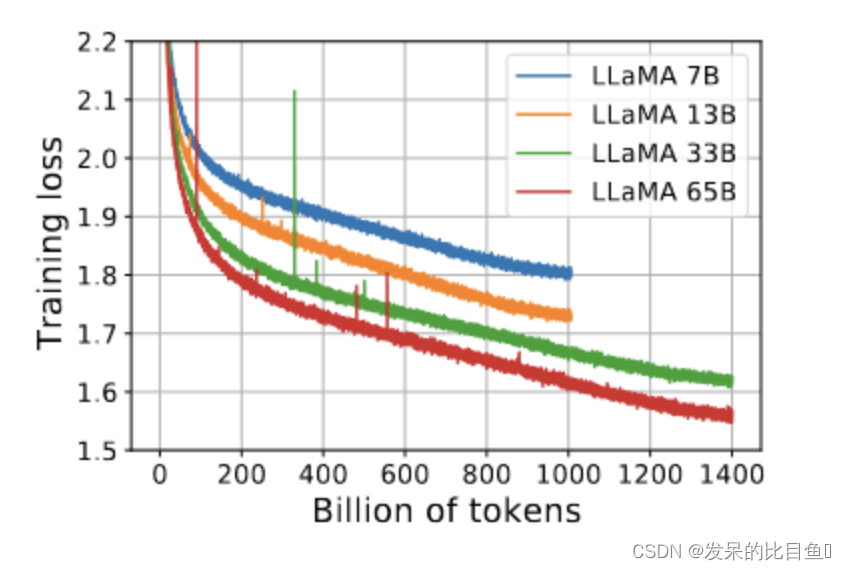
2023-arxiv-LLaMA: Open and Efficient Foundation Language Models
开放和高效的基础语言模型 Paper:https://arxiv.org/abs/2302.13971 Code: https://github.com/facebookresearch/llama
摘要
本文介绍了 LLaMA,这是⼀个包含 7B 到 65B 参数的基础语⾔模型的集合。作者在数万亿个令牌上训练模型,并表明可以…
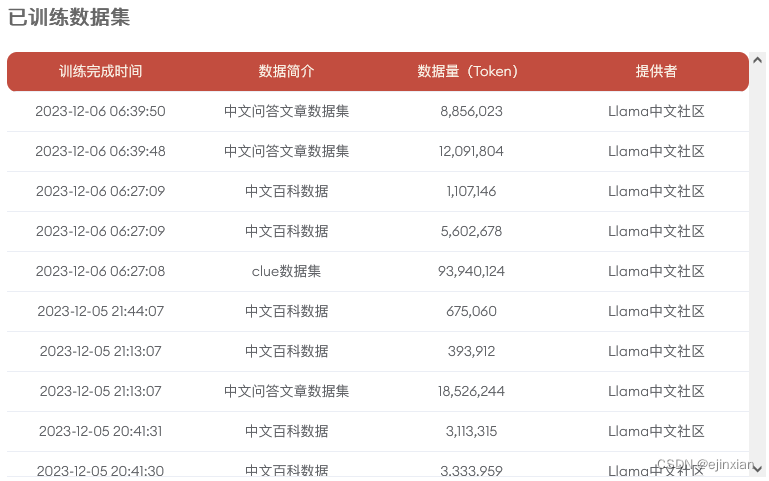
预训练大模型最佳Llama开源社区中文版Llama2
Llama中文社区率先完成了国内首个真正意义上的中文版Llama2-13B大模型,从模型底层实现了Llama2中文能力的大幅优化和提升。毋庸置疑,中文版Llama2一经发布将开启国内大模型新时代。 作为AI领域最强大的开源大模型,Llama2基于2万亿token数据预…
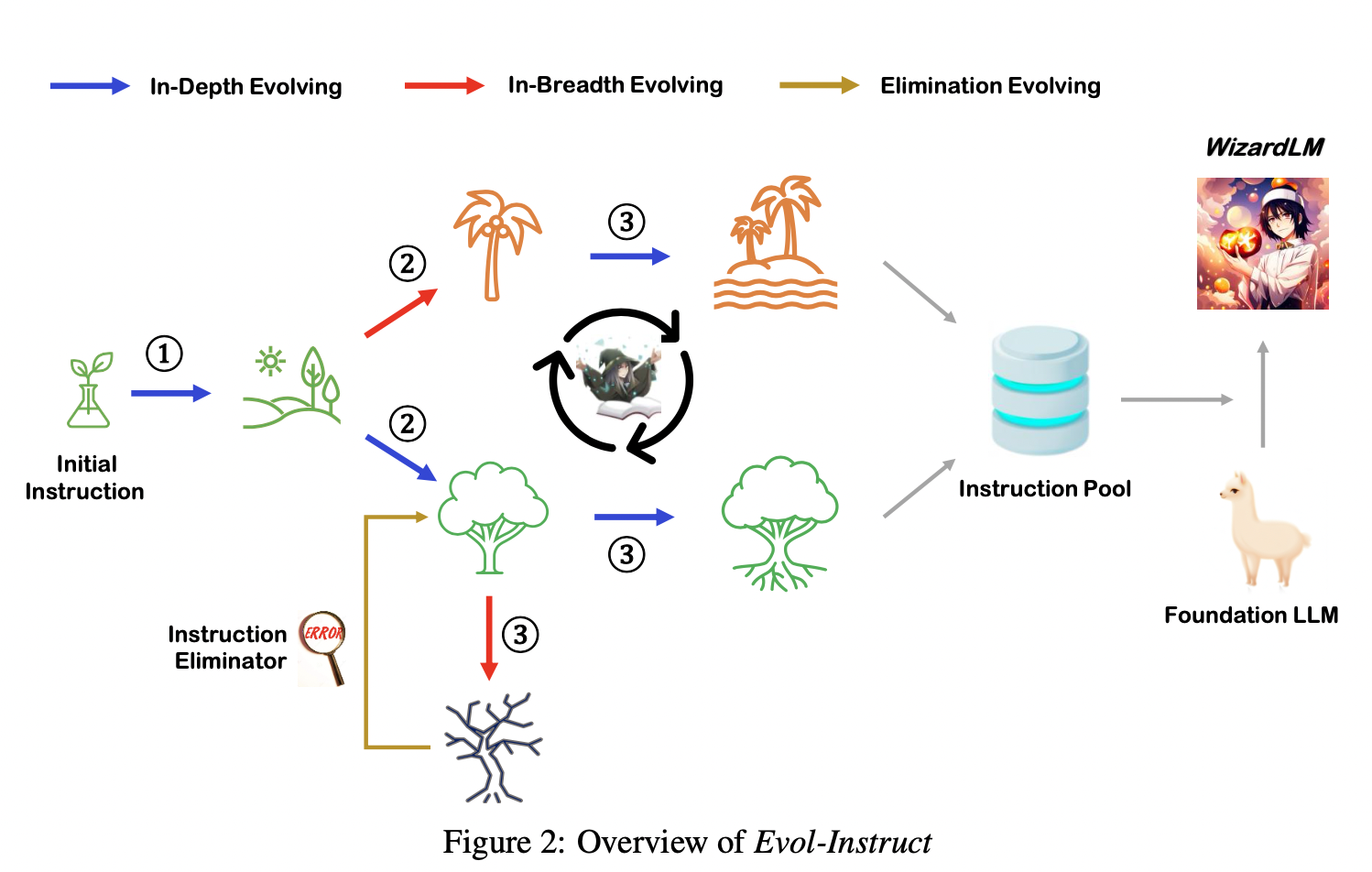
Text-to-SQL小白入门(四)指令进化大模型WizardLM
摘要
本文主要对大模型WizardLM的基本信息进行了简单介绍,展示了WizardLM取得的优秀性能,分析了论文的核心——指令进化方法。
论文概述
基本信息
英文标题:WizardLM: Empowering Large Language Models to Follow Complex Instructions中…
打造生产级Llama大模型服务
对于任何想要尝试人工智能或本地LLM,又不想因为意外的云账单或 API 费用而感到震惊的人,我可以告诉你我自己的旅程是如何的,以及如何开始使用廉价的消费级硬件执行Llama2 推理 。
这个项目一直在以非常活跃的速度发展,这使得它非…
本地部署CodeLlama +GTX1080显卡 对接open-interpreter对接wxbot(一)
1.效果展示 开源项目GitHub - oobabooga/text-generation-webui: A Gradio web UI for Large Language Models. Supports transformers, GPTQ, llama.cpp (GGUF), Llama models.
"Code Llama" 是一个大型代码语言模型的系列,基于 "Llama 2" 构建,为编程…
大语言模型LLM知多少?
你知道哪些流行的大语言模型?你都体验过哪写? GPT-4,Llamma2, T5, BERT 还是 BART?
1.GPT-4
1.1.GPT-4 模型介绍
GPT-4(Generative Pre-trained Transformer 4)是由OpenAI开发的一种大型语言模型。GPT-4是前作GPT系列模型的进一步改进,旨在提高语言理解和生成的能力,…
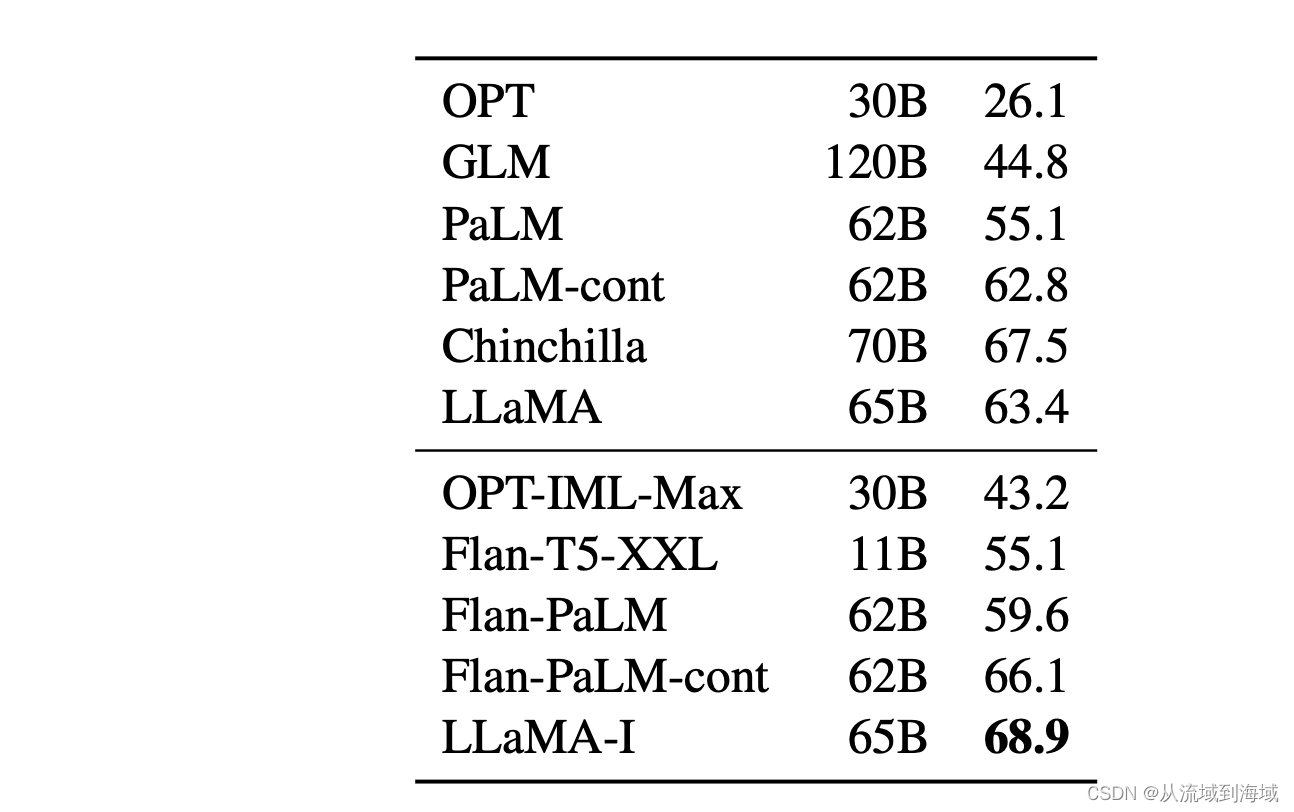
大语言模型之十五-预训练和监督微调中文LLama-2
这篇博客是继《大语言模型之十二 SentencePiece扩充LLama2中文词汇》、《大语言模型之十三 LLama2中文推理》和《大语言模型之十四-PEFT的LoRA》 前面博客演示了中文词汇的扩充以及给予LoRA方法的预训练模型参数合并,并没有给出LoRA模型参数是如何训练得出的。 本篇…
最强英文开源模型LLaMA架构探秘,从原理到源码
导读: LLaMA 65B是由Meta AI(原Facebook AI)发布并宣布开源的真正意义上的千亿级别大语言模型,发布之初(2023年2月24日)曾引起不小的轰动。LLaMA的横空出世,更像是模型大战中一个搅局者。虽然它…
非工程师指南: 训练 LLaMA 2 聊天机器人
引言 本教程将向你展示在不编写一行代码的情况下,如何构建自己的开源 ChatGPT,这样人人都能构建自己的聊天模型。我们将以 LLaMA 2 基础模型为例,在开源指令数据集上针对聊天场景对其进行微调,并将微调后的模型部署到一个可分享的…
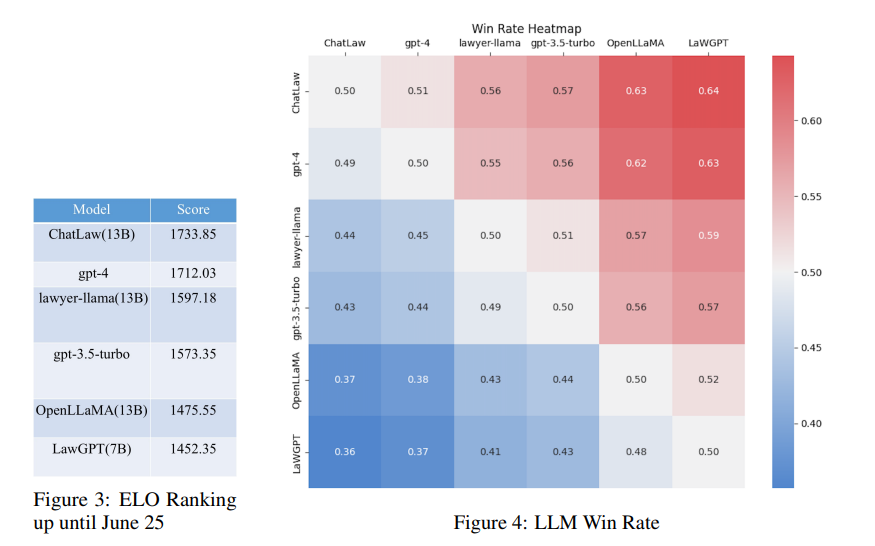
ChatLaw:基于LLaMA微调的法律大模型
文章目录 动机数据组成模型框架模型评估 北大团队发布首个的中文法律大模型落地产品ChatLaw,为大众提供普惠法律服务。模型支持文件、语音输出,同时支持法律文书写作、法律建议、法律援助推荐。 github地址:https://github.com/PKU-YuanGroup…
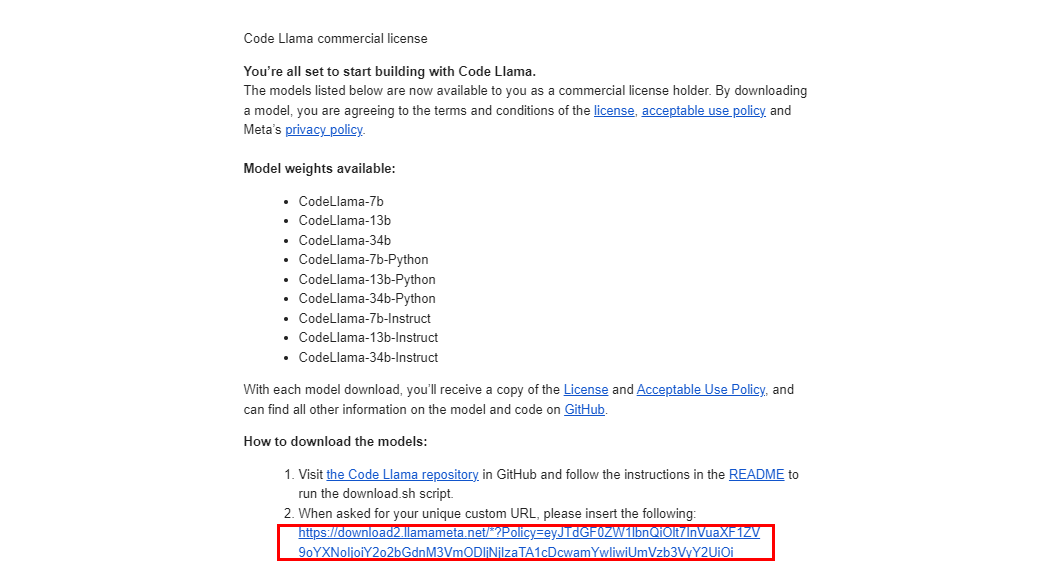
Meta开源大模型LLaMA2的部署使用
LLaMA2的部署使用 LLaMA2申请下载下载模型启动运行Llama2模型文本补全任务实现聊天任务LLaMA2编程Web UI操作 LLaMA2
申请下载
访问meta ai申请模型下载,注意有地区限制,建议选其他国家 申请后会收到邮件,内含一个下载URL地址,…
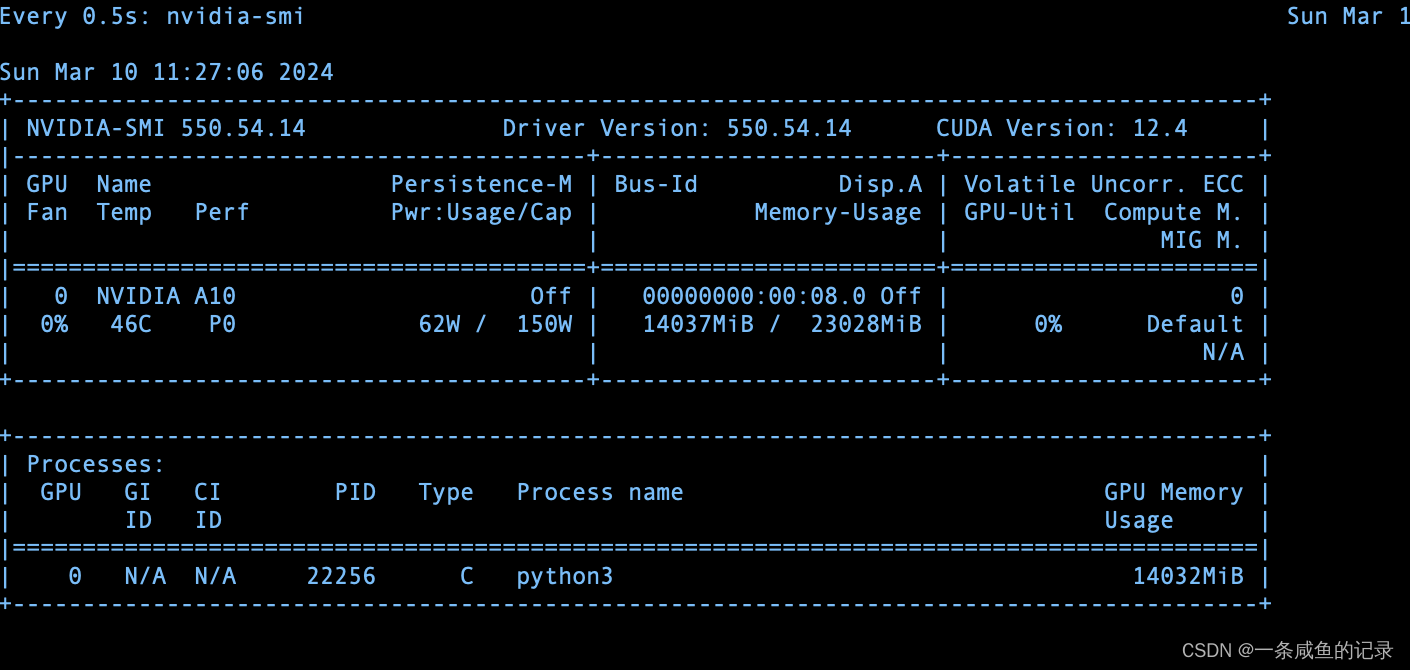
【个人开发】llama2部署实践(三)——python部署llama服务(基于GPU加速)
1.python环境准备
注:llama-cpp-python安装一定要带上前面的参数安装,如果仅用pip install装,启动服务时并没将模型加载到GPU里面。
# CMAKE_ARGS"-DLLAMA_METALon" FORCE_CMAKE1 pip install llama-cpp-python
CMAKE_ARGS"…
在Redhat 7 Linux上安装llama.cpp
正常安装的错误信息
安装 gcc 和gcc-c 之后,你运行Make 命令编译llama.cpp的时候,你会发现下面问题。
yum -y install gcc --nogpgcheckyum -y install gcc-c --nogpgcheck
错误信息, 因为gcc 的版本是4.8
cc -I. -Icommon -D_XOPEN_SOU…
llama-factory简介
llamafactory是什么,能干什么
LLaMA-Factory 是一个易于使用的大规模语言模型(Large Language Model, LLM)微调框架,它支持多种模型,包括 LLaMA、BLOOM、Mistral、Baichuan、Qwen 和 ChatGLM 等。该框架旨在简化大型语…
Llama中文大模型-模型量化
对中文微调的模型参数进行了量化,方便以更少的计算资源运行。目前已经在Hugging Face上传了13B中文微调模型FlagAlpha/Llama2-Chinese-13b-Chat的4bit压缩版本FlagAlpha/Llama2-Chinese-13b-Chat-4bit,具体调用方式如下:
环境准备࿱…

【AI】如何创建自己的自定义ChatGPT
如何创建自己的自定义ChatGPT 目录 如何创建自己的自定义ChatGPT大型语言模型(LLM)GPT模型ChatGPTOpenAI APILlamaIndexLangChain参考推荐超级课程: Docker快速入门到精通Kubernetes入门到大师通关课本文将记录如何使用OpenAI GPT-3.5模型、LlamaIndex和LangChain创建自己的…
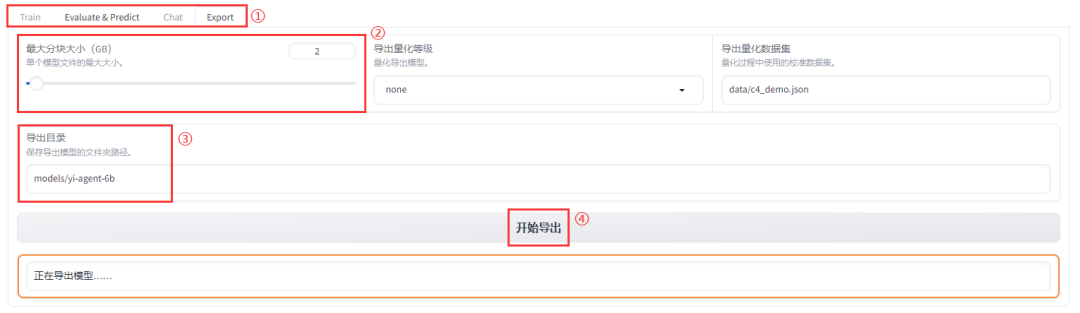
基于LLaMA Factory,单卡3小时训练专属大模型 Agent
大家好,今天给大家带来一篇 Agent 微调实战文章
Agent(智能体)是当今 LLM(大模型)应用的热门话题 [1],通过任务分解(task planning)、工具调用(tool using)和…
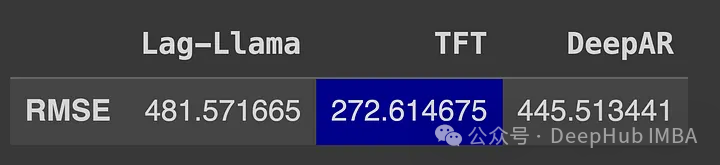
Lag-Llama:第一个时间序列预测的开源基础模型介绍和性能测试
2023年10月,我们发表了一篇关于TimeGPT的文章,TimeGPT是时间序列预测的第一个基础模型之一,具有零样本推理、异常检测和共形预测能力。
虽然TimeGPT是一个专有模型,只能通过API访问。但是它还是引发了对时间序列基础模型的更多研…
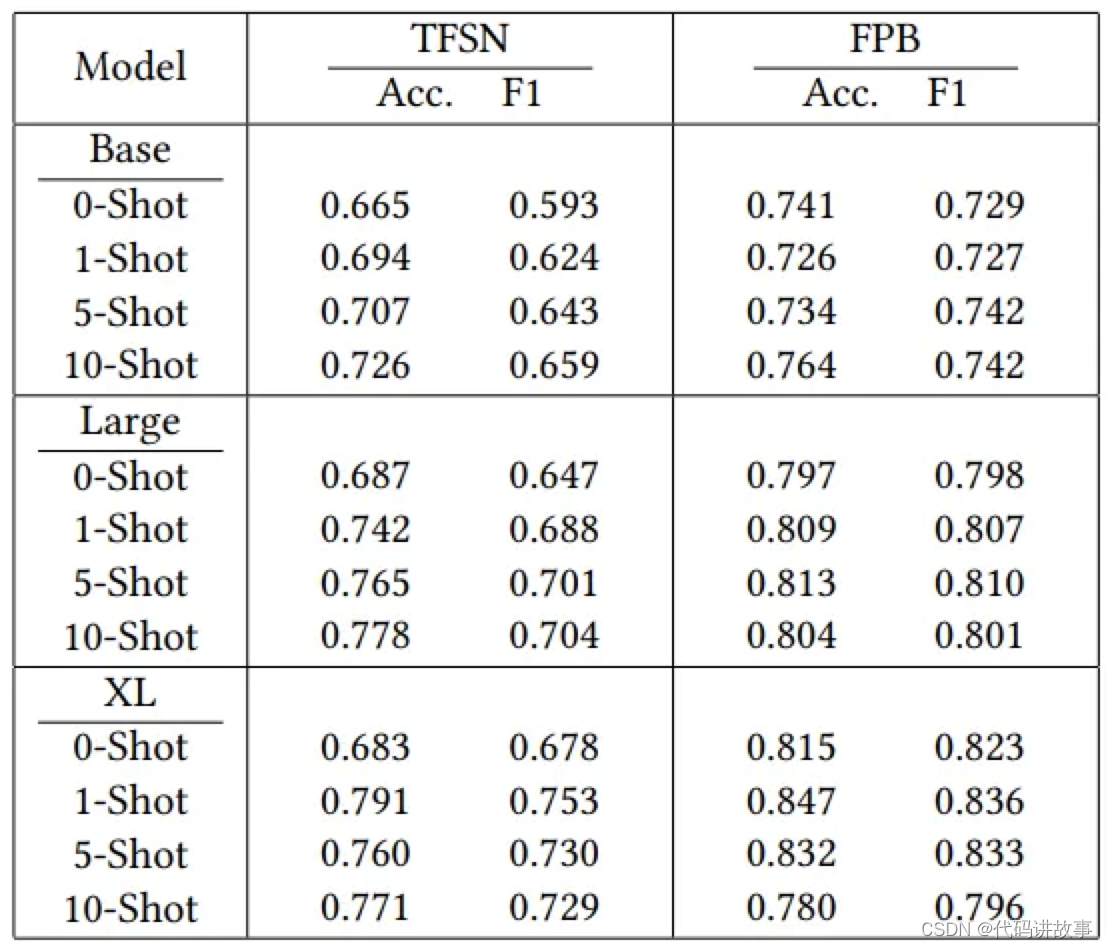
轻量级模型,重量级性能,TinyLlama、LiteLlama小模型火起来了,针对特定领域较小的语言模型是否与较大的模型同样有效?
轻量级模型,重量级性能,TinyLlama、LiteLlama小模型火起来了,针对特定领域较小的语言模型是否与较大的模型同样有效? 当大家都在研究大模型(LLM)参数规模达到百亿甚至千亿级别的同时,小巧且兼具高性能的小…

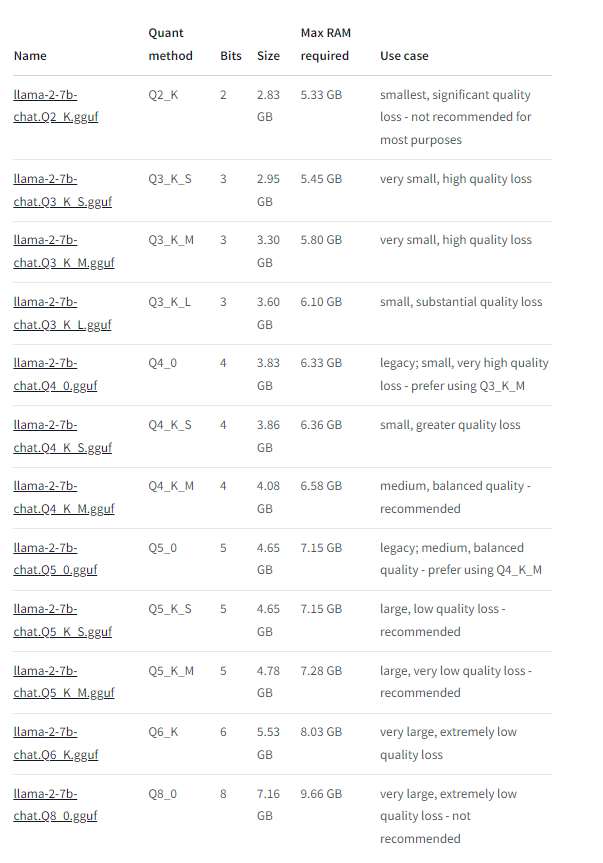
用GGUF和Llama .cpp量化Llama模型
用GGUF和Llama .cpp量化Llama模型 什么是GGML如何用GGML量化llm使用GGML进行量化NF4 vs. GGML vs. GPTQ结论 由于大型语言模型(LLMS)的庞大规模,量化已成为有效运行它们的必要技术。通过降低其权重的精度,您可以节省内存并加快推理…